计算机组成原理#
- 内核态与用户态:计算机刚开机的时候,硬盘的kernel内核程序先加载,然后才启动上层的各种app应用文件。
- kernel启动的时候会先在内存中开启
内核空间,或者内核态。剩余的部分给用户态、用户空间 用户态的应用程序无法直接访问内核态的内存,必须调用内核的“系统调用”才可以。(system call ,在man里面是2类)- 应用程序去调用的“系统调用”需要通过【中断】的方式找到内核的方法实现,CPU切换到内核态,内核中断去访问硬件
中断#
-
背景:CPU内部有
晶振元件,通电后在一定时间内振动固定的次数。当晶振一定次数后,产生“时间中断”,就产生了所谓CPU时间片。 -
1.内核启动的时候会产生一个进程调度的回调地址Callback
-
2.CPU产生中断的时候会把缓存刷回程序内存,保护现场。
-
3.然后调用内核的callback,根据不同优先级调用的不同进程回调地址。(从主存里面把曾经刷过去的缓存再加载到CPU缓存)
-
4.下次晶振再重复上面的过程,就完成了进程切换的过程。
-
**缺点:**如果进程很多,切换成本很高,比如切换过去后发现在阻塞,其实是一种浪费。
-
软中断:因为应用程序需要进行系统调用,调用内核态。会发生用户态到内核态的切换。CPU需要刷缓存,调用callback,传递参数,再回来。- 系统调用是一个软中断,中断号是0x80,它是上层应用程序与Linux系统内核进行交互通信的唯一接口。
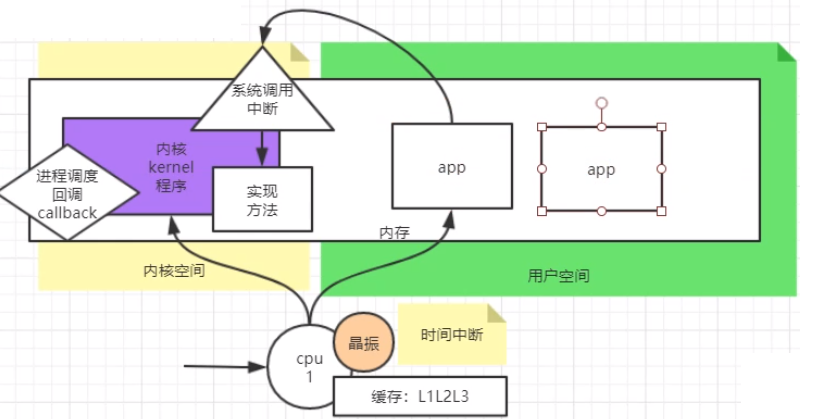
我们有多个应用,应用IO的变化是由内核的变化来实现的。
硬件中断#
-
我们有多个硬件设备,比如键盘、鼠标、网卡,当他们发生动作的时候如何让OS响应?也是通过调用中断。
-
比如鼠标点击的时候调用CPU中断,传递参数生成一个事件event。CPU去调用kernel(kernel启动的时候通过设备的驱动程序获取了中断号和callback。包括中断信号,和执行的方法)
-
然后kernel根据对应的callback程序做出正确的响应即可。
-
网卡为了避免频繁发送中断,使得降低CPU的浪费,会在内存中被分配极小一块缓存区域(DMA区域 直接内存),攒够了发一次中断。是一个
buffer思想。

IO 升级发展之路#
经典CS架构的BIO#
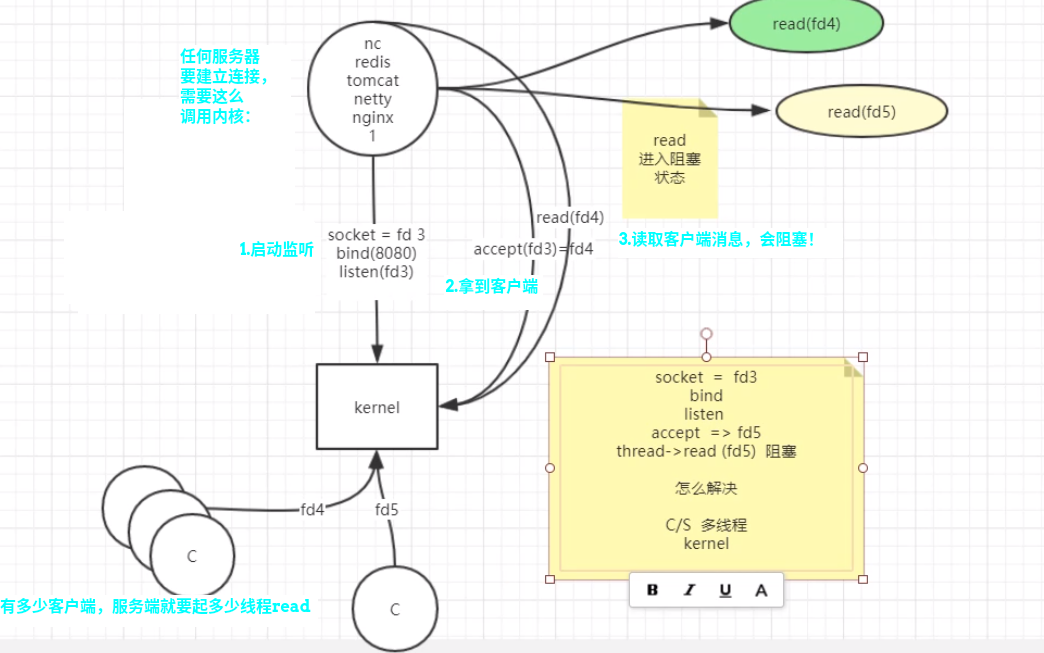
- 任何服务想要启动监听接受请求,需要进行以下步骤
- 1.调用kernel启动一个socket的文件描述符,假设叫fd3,监听
- 2.死循环去调用kernel的accept(fd3)方法,去不断获取最新的客户端文件描述符,假设获得一个客户端fd4
- 3.去调用kernel的read(fd4)方法读取客户端的消息,read这是一个阻塞方法!!!
- 4.为了不阻塞,只能accept拿到每一个客户端之后,read去启动一个线程,线程里面去阻塞读取用户消息。
弊端:有多少客户端连接,就要启动多少线程,资源浪费极大。而且多线程的数据共享、调度都很麻烦。
1 | // 伪代码 |
【痛点】:kernel的read(fd)操作是阻塞的(在等待对端发消息),会需要很多线程,但是多线程开销太大,kernel的调度也很费劲。
C10K问题#
最初的服务器是基于进程/线程模型。新到来一个TCP连接,就需要分配一个进程/线程。假如有C10K也即是1W个客户端,就需要创建1W个进程/线程,可想而知单机是无法承受的。那么如何突破单机性能是高性能网络编程必须要面对的问题,进而这些局限和问题就统称为C10K问题,最早是由Dan Kegel进行归纳和总结的,并且他也系统的分析和提出解决方案。
【问题本质】:是操作系统的问题,创建的进程或线程多了,数据拷贝频繁(缓存I/O、内核将数据拷贝到用户进程空间、阻塞,进程/线程上下文切换消耗大, 导致操作系统崩溃,这就是C10K问题的本质。
【解决方案】:
同一个线程/进程同时处理多个连接---------------------多路复用。
kernel的非阻塞的read与多路复用器(NIO时代)#
kernel进化了,支持了一个应用层面非阻塞的read接口,所以我们应用就可以同上类似:
-
任何服务想要启动监听接受请求,需要进行以下步骤
-
1.调用kernel启动一个socket的文件描述符,假设叫fd3,监听
-
2.死循环去调用kernel的accept(fd3)方法,去不断获取最新的客户端文件描述符,假设获得一个客户端fd4
-
3.去调用kernel的非阻塞read(fd4)方法读取客户端的消息,这是一个非阻塞方法。有内容就给你,没有就给一个没有个的返回或者异常。调用后就该干嘛干嘛去,待会儿再来。
-
4.不用去开启线程,直接循环回到第2步骤,再去获取客户端。(截止这一轮2个客户端的话保存一个fd的数组)
-
5.上面的第3步循环这个客户端fd的数组,逐个去调用kernel的非阻塞read(each_fd)方法,拿到返回继续会到2…
1
2
3
4
5
6
7
8while(true){
client_fd = accept(server监听的fd) // 获取客户端的监听,调用内核态
clients.add(client_df) // 存储一个新的客户端
for(each_fd in clients){
msg = read(each_fd) // 非阻塞读取到消息,非阻塞调用内核态
// 业务处理
}
}
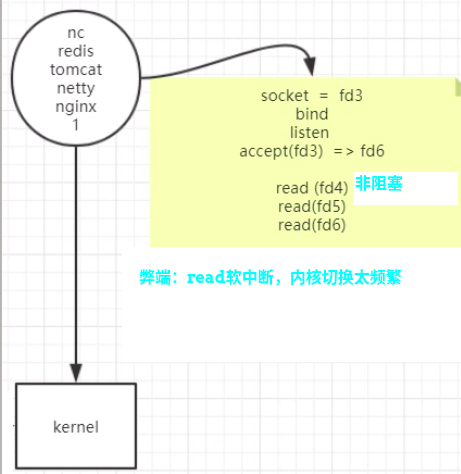
或者可以启动2个线程,一个Boss线程去死循环专门获取客户端的连接,一个Worker线程去专门死循环所有的客户端非阻塞读取消息。----------是不是有Netty的感觉了?
【弊端】:工作线程的worker虽然都不是阻塞的,不用启动多线程。但是还是要进行系统调用,也就是调用内核。调用内核是通过软中断实现的。用户态到内核态的切换太频繁。
比如10w的fd客户端,work线程每次循环需要调用10w次kernel的read方法,发生10w次用户态和内核态的切换。但是可能只有10个人发消息了,绝大部分的内核切换都浪费了。read的调用是O(n)的。
现在的JDK的NIO包中已经使用了多路复用器解决,见下节。
多路复用器实现—select/poll和epoll#
kernel发生变化,我们才能突破。如果无法解决上面例子中10w个fd需要10w次调用才能传给kernel的问题,就无法改进。
第一类多路复用器—select和poll#
man 2 select可以看到内核的select多路复用情况。
【多路 复用】:假设10w个客户端fd,把原先需要调用10w次read(each_fd)读取消息,复用成select(fds),返回有消息的fd集合。
select多路复用器带来的改变:
- 任何服务想要启动监听接受请求,需要进行以下步骤
- 1.调用kernel启动一个socket的文件描述符,假设叫fd3,监听
- 2.死循环去调用kernel的accept(fd3)方法,去不断获取最新的客户端文件描述符,假设获得一个客户端fd4,多个积攒的客户端得到一个fd的集合fds
- 3.去调用一次kernel的select(fds)方法,kernel去把所有的fd进行检查,把发生消息变化的fd集合返回!【循环发生在kernel里面,没有用户态和内核态的切换】
- 4.程序只用去调用上面有消息的一小部分fd的read(each_fd)方法,就能读取到消息
- 5.回到2循环…
【优势】:大大减少内核态和用户态的切换。例子中一次调用复用了10w次read,后续统一处理返回的个别有消息的fd。
【弊端】:
- 1.每次循环调用select的时候,都要copy 10w个fd的数据从用户态到内核态。(内核能记住之前的客户端多好?)
- 2.内核态还需要把这10w个fd每次都循环检查一遍。
select支持的fd是有上限的,需要重新编译内核才行很费劲,默认只支持1024个fd的多路复用。
poll改进:使用一个链表结构突破限制,支持无上限的fd集合一起传输。只依赖于操作系统的ulimites设置
第二类多路复用器----epoll-IO/Event Notifycation facility#
epoll是一个多路复用的进阶版,改进了客户端fd频繁copy到内核态的问题。是同步非阻塞的。是C10K问题的进阶版。
-
系统级同步:程序还是需要去主动调用kernel的read方法获取数据
-
系统级异步:程序给一个内核级别的callback,发生事件的时候直接到callback,接收到数据。------epoll做不到。
epoll工作原理:#
epoll不用去轮询监听所有文件句柄是否已经就绪。epoll只对发生变化的文件句柄感兴趣。
有epoll_create(2)、epoll_ctl(2)、epoll_wait(2)组成(2是系统调用)。
- 其中
epoll_create创建一个epoll实例,返回一个文件描述符,代表内核空间。 epoll_ctl,将我们的client订阅关注的事件去丢到内核空间(每个client只用丢一次)epoll_wait去阻塞,或者超时查看发生状态变化的client的fd,拿到后去处理。
使用"事件"的就绪通知方式,通过epoll_ctl注册文件描述符fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd, epoll_wait便可以收到通知, 并通知应用程序。
man epoll 看一眼帮助:
首先EPOLL(7) 是一个杂项,由三个2类的系统调用组成:epoll_create(2)、epoll_ctl(2)、epoll_wait(2)
1 | EPOLL(7) Linux Programmer's Manual EPOLL(7) |
epoll_create 系统调用#
可以去man 2 epoll_create看一眼这个系统调用(2类)的epoll的帮助,看他的返回:
1 | EPOLL_CREATE(2) Linux Programmer's Manual EPOLL_CREATE(2) |
他的返回是: On success, these system calls return a nonnegative file descriptor. On error, -1 is returned, and errno is set to indicate the error.
这个返回是一个fd,它代表的是一个内核空间------------保存我们的客户端fd。这些客户端怎么放进去的呢?epoll_ctl可以往里面添加fd
epoll_ctl-增删改fd给到内核空间#
一样我们看一下帮助man 2 epoll_ctl可以看到int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);这是一个系统调用,epfd可以传递客户端的fd,op可以传递EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL去增删改。一个客户端只用放一次,以后再也不用放了。
1 | EPOLL_CTL(2) Linux Programmer's Manual EPOLL_CTL(2) |
epoll_wait-让fd等待事件#
同上类似man 2 epoll_wait
1 | EPOLL_WAIT(2) Linux Programmer's Manual EPOLL_WAIT(2) |
epoll工作流程#
【Epoll】:假设10w个客户端fd
- 任何服务想要启动监听接受请求,需要进行以下步骤
- 1.调用kernel启动一个socket的文件描述符,假设叫fd3,监听
- 2.调用
epoll_create,创建epoll实例,会在内核中开辟空间假设fd6。 - 3.调用
epoll_ctl(fd6, ADD , fd3, event_accept),把socket fd3加入内核空间fd6中,同时监听accept事件。 - 4.调用
epoll_wait(fd6,res),等待fd6中的所有fd返回,阻塞,也可以可以超时。传递一个res是接受返回的内存空间。 - 假设上面
epoll_wait的时候,一个C1来了三次握手,制造事件中断。CPU回调,知道来了一个客户端,就把这个fd放到fd3上。fd3就放到上面给的res。(accept) - 5.
epoll_wait从res看到有fd3的accept了,把这个fd3给到程序去执行accept(fd3),得到一个fd8.这时候fd8就代表下面的C1客户端了。 - 6.调用
epoll_ctl(fd6, ADD , fd8, event_read),把客户端fd8加入内核空间fd6中,同时监听read事件。(以后就不用监听了) - 7.程序循环调用
epoll_wait(fd6,res),等待fd6中的所有fd返回,阻塞,也可以可以超时。传递一个res是接受返回的内存空间。拿出res里面的fd和事件去处理。 - 这时候C2如果来了,fd6里面监听了accept和read,都会触发中断。CPU会把fd3和fd8都放到res,注明有一个连接来了俩event。
- 这时候epoll_wait会返回两个fd,fd3里面的event拿出来会得到一个新的client,命名fd9,来代表C2.
- 然后把fd9也调用
epoll_ctl(fd6, ADD , fd9, event_read)加进去,内核就多监听一个中断事件。

多而两个系统调用
epoll空间开辟早期的时候用mmap(程序和内核都可以访问),后来系统调用不用这个实现了,因为多线程的时候mmap有点问题。
上层开辟线程,传递数据的时候还是用的mmap。内存直接访问。
【优势】:压榨硬件资源到极致,规避了客户端fd的频繁拷贝。事件驱动。
【缺点】:epoll只完成了event的通知,需要拿到数据的时候还是需要去同步调用read。(可以非阻塞调用read,但是还是程序需要主动调用read,不会直接给到)
epoll不一定是最快的,根据client的特点?
也就是网卡把数据放到DMA区域,内核通过中断只知道DMA有数据,有事件。kernel知道是什么时间类型,会通过epoll_wait的res告诉程序,但是不会直接把消息读取出来。还是需要应用app去调用kernel的read(阻塞或者非阻塞)去拿回数据。
思想:事件到达了,会有event告诉内核。
select/poll和epoll的对比#
select和poll是一类 epoll是另一类
| 支持一个进程所能打开的最大连接数 | FD剧增后带来的IO效率问题 | 消息传递方式 | |
|---|---|---|---|
| select | 单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。 | 因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 | 内核需要将消息传递到用户空间,都需要内核拷贝动作 |
| poll | poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 | 同上 | 同上 |
| epoll | 虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接 | epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 | epoll通过内核和用户空间共享一块内存来实现的。 |
AIO#
aio on linux比较费劲,因为linux希望更多的CPU运行在用户空间,内核空间保证安全。
如果AIO如何搞定系统级别异步?linux kernel去执行应用定义的callback?在哪里启动callback的线程?这个callback在哪里执行?kernel执行的话安全性?
TCP基础#
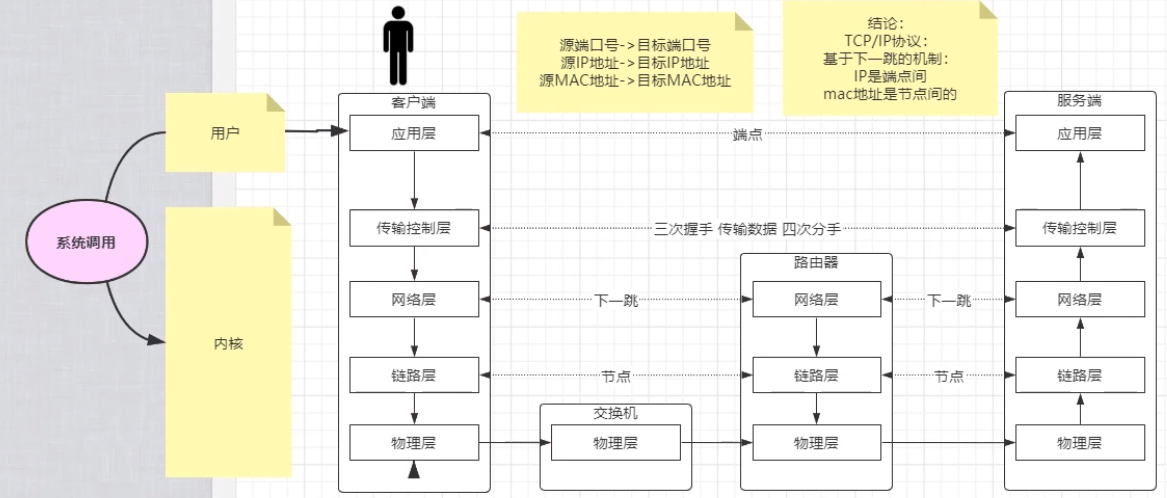
OSI基础模型#
提到IO,首先是OSI参考模型,计算机网络基础,一共七层
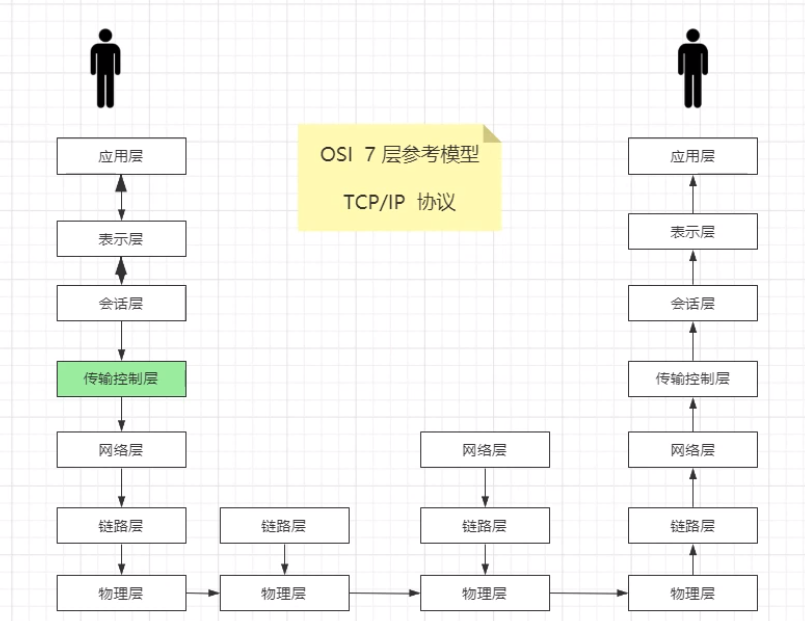
这7层是一个虚的东西,是一个规范。TCP/IP协议给精简到4层,把上面的应用层-表示层-会话层统一归结到新的应用层是用户称,把下面的传输控制层-网络层-链路层-物理层视为内核层。
| OSI七层网络模型 | TCP/IP四层概念模型 | 对应网络协议 |
|---|---|---|
| 应用层(Application) | 应 | HTTP、TFTP, FTP, NFS, WAIS、SMTP |
| 表示层(Presentation) | 用 | Telnet, Rlogin, SNMP, Gopher |
| 会话层(Session) | 层 | SMTP, DNS |
| 传输层(Transport) | 传输层 | TCP, UDP |
| 网络层(Network) | 网络层 | IP, ICMP, ARP, RARP, AKP, UUCP |
| 数据链路层(Data Link) | 数据 | FDDI, Ethernet, Arpanet, PDN, SLIP, PPP |
| 物理层(Physical) | 链路层 | IEEE 802.1A, IEEE 802.2到IEEE 802.11 |
linux命令测试讲解TCP#
创建一个到baidu的文件描述符(内核层)#
- linux一切皆文件,每一个程序都有自己的IO流。程序里面的IO流也会被描述成文件(数字)。没一个程序都有3个自带的文件描述符:
- 0:system.in
- 1: system.out
- 2: system.err
- 用户创建的IO就从3开始
**【举例】**执行一个bash命令创建一个到baidu的socket,IO流重定向到当前进程的8号文件描述符中:
-
exec 8<> /dev/tcp/www.baidu.com/80 -
上面面创建了一个文件描述符“8”,是一个socket指向了百度,
-
8是文件描述符fd(就像代码的变量),<>是一个双向输入输出流,可以看到
-
echo $$ # 打印当前命令行的进程号 16199 # 也可以ps -ef 然后grep出来 tree 16199 9368 0 4月15 pts/1 00:00:01 /bin/bash1
2
3
4
5
6
7
8
9
10
11
12
- 可以去当前进程的目录看一眼
- ```bash
cd /proc/16199/fd # 进入当前进程的fd目录
ls # 看一眼
lrwx------ 1 tree tree 64 5月 21 18:31 0 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 1 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 2 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 255 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 8 -> 'socket:[1037956]'
# 每个进程都有0,1,2三个fd文件描述符。分别是stdin、stdout、stderr
向文件描述符中写东西通信(用户层态)#
1 | echo -e "GET / HTTP/1.0\n" 1>& 8 |
传输控制层TCP协议#
TCP和UDP是传输控制层协议。
什么是socket套接字?#
-
ip+port <---------> ip+port是一【套】,客户端和服务端的ip+port 4个要素决定唯一的一个socket -
客户端的ip是B,可以和baidu建立多少个链接?65535个
-
此时客户端B还能继续和163建立链接吗?也可以继续再次建立65535个,因为socket是【一套】4个要素,server换了就是另外一个socket了。
-
对于类似如下
netstat -anp出来的socket链接,每一个established都有一个文件描述符(fd目录下)数字和他对应并交给一个进程。程序只用和这个文件描述符进行读写就可以进行socket通信了。【如果多个socket对应一个进程:就是多路复用器selector或者epoll】下面的
192.168.150.12:22建立了两个到192.168.150.1的socket: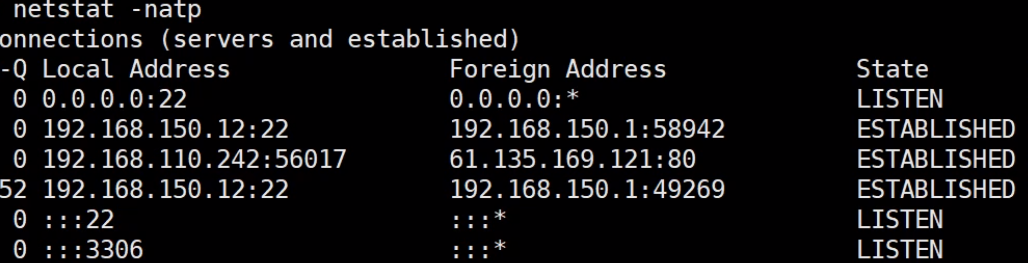
什么是TCP协议?#
是一个面向连接的可靠的传输协议。因为三次握手保证了可靠传输。
连接:不是物理连接,是三次握手实现的逻辑连接,完成双向确认。
为啥可靠:通信前三次握手双方分配资源,为未来的通讯做好了准备。所有数据包发送的时候有个确认机制保证了可靠。
DDOS:发握手包,但是不回。造成服务器有一大堆接受TCP的等待队列。使得真正想进来的连接进不来。
三次握手的细节?#
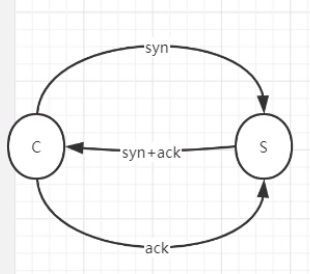
C-----------syn----------->S # “我要跟你连接了,标识是syn”
C<----------syn+ack-------S # “好的,我知道了” 让客户端知道Server已经响应了
C------------ack----------->S # 好的,我知道你知道了。让Server知道发出的消息客户端收到了
然后双方开始开辟资源(内存,结构体,线程),建立连接。
谁触发三次握手?目的?#
应用层的程序先告诉内核,我要和一个地址建立连接。内核去尝试三次握手。
三次握手成功后会在双方服务器开辟资源(线程、内存结构体等等)来为对方提供响应服务。
三次握手完毕后,双方才有资源开辟,才能开始传输。
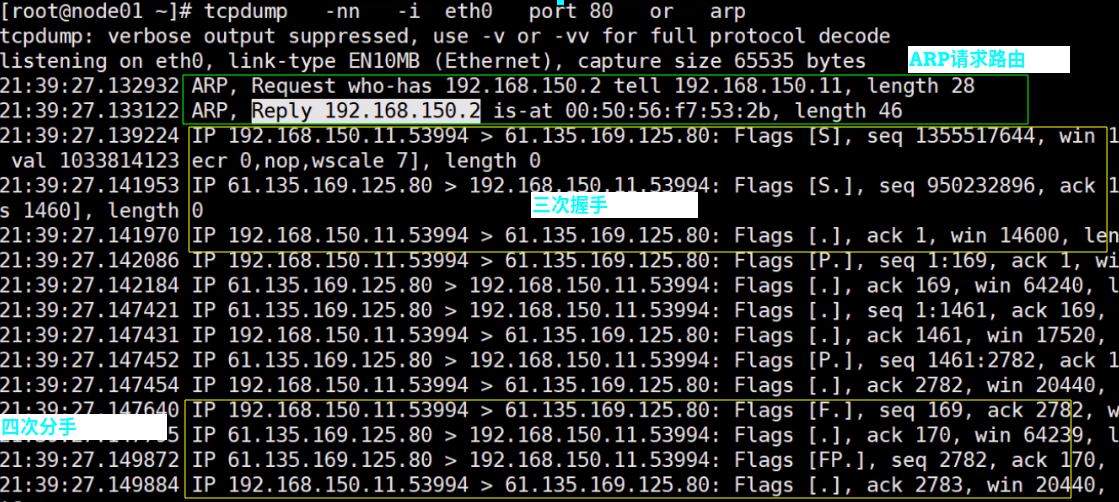
tcpdump 查看三次握手#
tcpdump -nn 显示ip断开 -i 显示哪个网卡接口 port 显示哪个端口

四次分手的细节,为啥要四次?#
因为握手是三次,开辟了资源。分手是双方一起释放资源,对对方有义务的,所以是四次(双方都要同时释放,不能轻易单方面释放了)
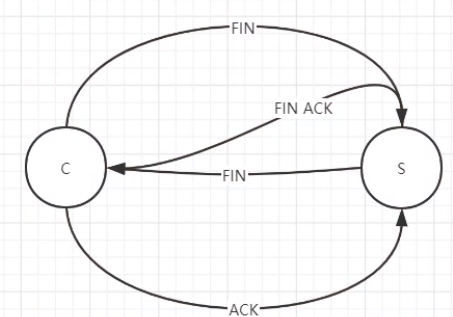
分手的C只是先说断开的人
C-----------fin----------->S # “我要跟你分手了,标识是fin”给Server一个结束标识
C<----------fin+ack-------S # “好的,我知道了” 让客户端知道Server已经响应了(但是我要确认一下真的没事儿了)
C<-----------fin------------S # “好吧,分吧,标识是fin”确认真的没事儿了,给客户端一个结束标识
C------------ack----------->S # “好的,”让Server知道发出的消息客户端收到了
然后双方把给对方准备的资源都释放了。
三次握手和四次分手是不可分割的最小粒度#
-
LVS作为一个工作在四层的负载均衡,是无法知晓数据包的具体内容的!
-
LVS是否可以随意把数据给后端进行负载?-可以负载,但是受制于协议约束!
- C ----- lvs ----- S1/S2 的时候,LVS必须要把握手的三次给到一对C—S,不能给到另外一个S,否则无法建立连接。
网络和路由#
上面的TCP协议只管传输和控制,也就是发什么内容,怎么发。但是发送的路径不管,是下层寻址ARP协议管理的。
网络设置要ip、gateway、mask、dns4个东西
- 如果几个设备ip:
192.168.1.10、192.168.1.11,他们只要成功联网,肯定知道他们的下一跳路由器地址(静态或者DHCP),如192.168.1.1 - 客户端向发送一个ARP广播包,带着路由器的ip和全
FFFFFFFFFF的mac地址,路由器收到后看到是自己的ip,就把自己的mac地址返回给客户机。 - 然后客户端才知道路由器的mac,包装后就能往百度发了三次握手的包了。
- 通过路由表往下一跳发
【测试】``
下面会先去请求ARP,收到路由器返回mac后,包装三次握手的包发出去。最后四次分手。
每次发送的包和接受的包都有一个seq和seq+1的关系,保证了不会错乱。
其他:#
关于DirectBuffer#
每个进程都有堆内存,JVM是C写的,启动的时候有堆空间。我们可以堆外分配空间直接给JVM访问。这个堆外空间除了内核共享,还可以接到磁盘文件上。
RandomAccessFile里面有direct分配空间和map(4096):可以使用RandomAccessFile打开文件,对着这个文件对象调用map。JVM就有堆外空间接到磁盘上了。map返回一个buffer,JVM直接把文件存到磁盘上了。不用调用kernel的write,减少一次系统调用。
mmap#
内核和应用共同访问的共享内存。mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。这样直接对内存的读写就完成了之前的系统调用read、write,速度更快,而且内核空间也可以对这个文件直接修改,可以完成进程间文件共享。
mongoDB (3.0以前版本) 、rocketMQ 都用到了 mmap
Kafka的IO优化?#
kafka是基于JVM的消息队列,读取消息的时候Client到Kernel调用系统调用read,再到kafka去解析。kafka优化对这个文件开启mmap映射,写文件的时候就像写buffer一样,越过系统调用直接落到磁盘。少了一次write系统调用。
kafka启动的时候有一个segment01段文件,就是mmap开辟的内存映射的大小,默认1G。对这1G的内存哪个位置放了,就会出现在文件的哪个位置。
segment把1G文件填满之后移动,再创建一个segment,再mmap一下得到第二个文件。
读:正常是程序调动kernel,kernel去读取文件到文件偏移量,拷贝到用户空间。用户空间把数据再发出去的时候又要调用kernel,多copy了一次。
如果数据是不需要kafka再加工的,就可以触发零拷贝:
程序调用sendfile,把输入输出的fd传进去,sendfile是在内核里实现的,所以直接零拷贝了。
man 2 sendfile
1 | SENDFILE(2) Linux Programmer's Manual SENDFILE(2) |
所以kafka用到mmap、零拷贝、epoll,性能高。redis底层也是epoll.
nginx也是epoll,还有sendfile的零拷贝,配置文件里面就有sendfile。
参考资料