Java多线程相关概要总结:#
- 一致性
- 线程相关:
- 线程实现、Runnable、Callable、Future、CompletableFuture
- golang纤程
- 锁相关:
- volatile实现
- synchronized实现
- AQS
- ReentrantLock实现
- CAS实现
- 其他JUC同步工具:
- CountDownAndLatch
- Condition、await、signal: 同步队列
- CyclicBarrier:
- 同步容器:
- Map、Set、List无锁
- ConcurrentHashMap
- ConcurrentSkipListSet
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- BlockingQueue
- BlockingDeque
- 线程池:
- 俩接口Executors和ExecutorService
- 基础实现ThreadPoolExecutor,和内置定义的newSingleThreadExecutor、newFixedThreadPool、newCachedThreadPool、ScheduledThreadPoolExecutor。所有线程都使用一个阻塞队列去排任务。
- ForkJoinPool和newWorkStealingPool:每个线程一个队列。根据阈值拆分、RecursiveTask、RecursiveAction
- 俩接口Executors和ExecutorService
- 引用类型:
- 强引用、软引用、弱引用、虚引用
- Disruptor:
- 目前单机性能最高的JVM内MQ(和BlockingQueue等比)
- RingBuffer、EventFactory、Event、缓存行
- JMH:
- Java MicroBenchmark Harnes:微基准测试。
- org.openjdk.jmh包,插件,@BenchMark @Warmup预热、@BenchmarkMode(Mode.Throughput)
多线程必要性#
-
压榨机器资源,废话。
-
服务隔离,高可用:首先一个JVM中的多个线程才能带来服务隔离,每一个线程完成自己的逻辑。如果一个线程从头走到尾,所有的业务都是自己,是做不到隔离的,崩溃就完蛋。多个可以做到降级,比如短信线程挂了,交易还能用。
并发容器介绍#
JDK的容器介绍#
大致分为Collection和Map两类,Collection下面又有传统的List和Set,以及更灵活的Queue
List和Set#
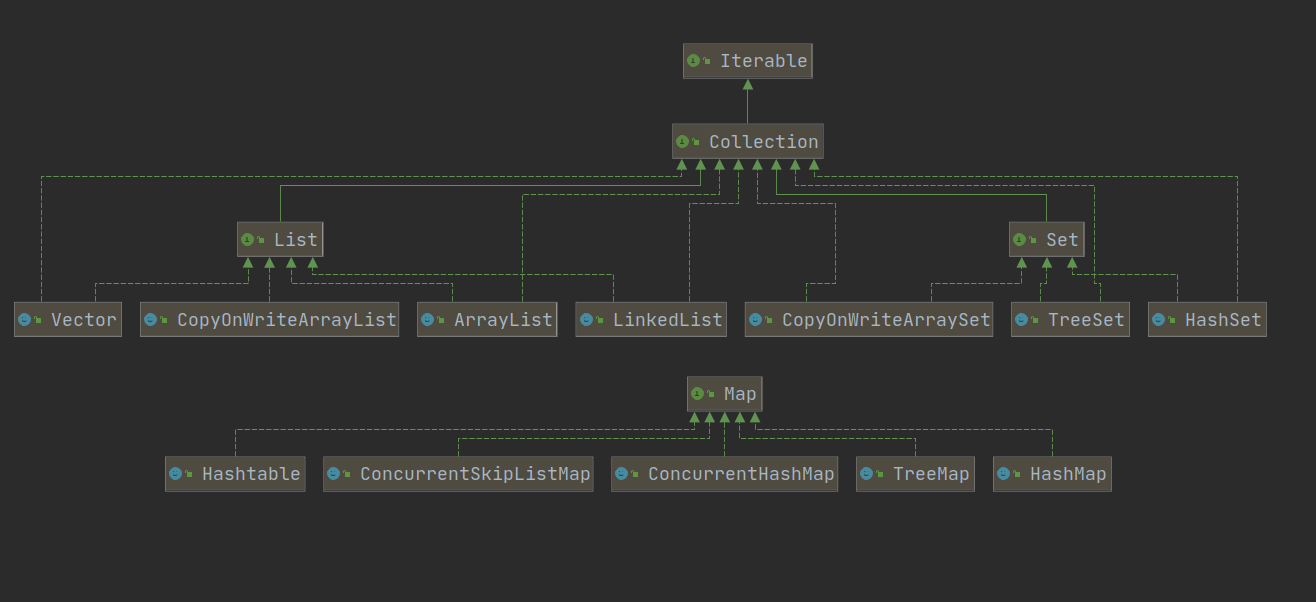
更灵活的Queue#
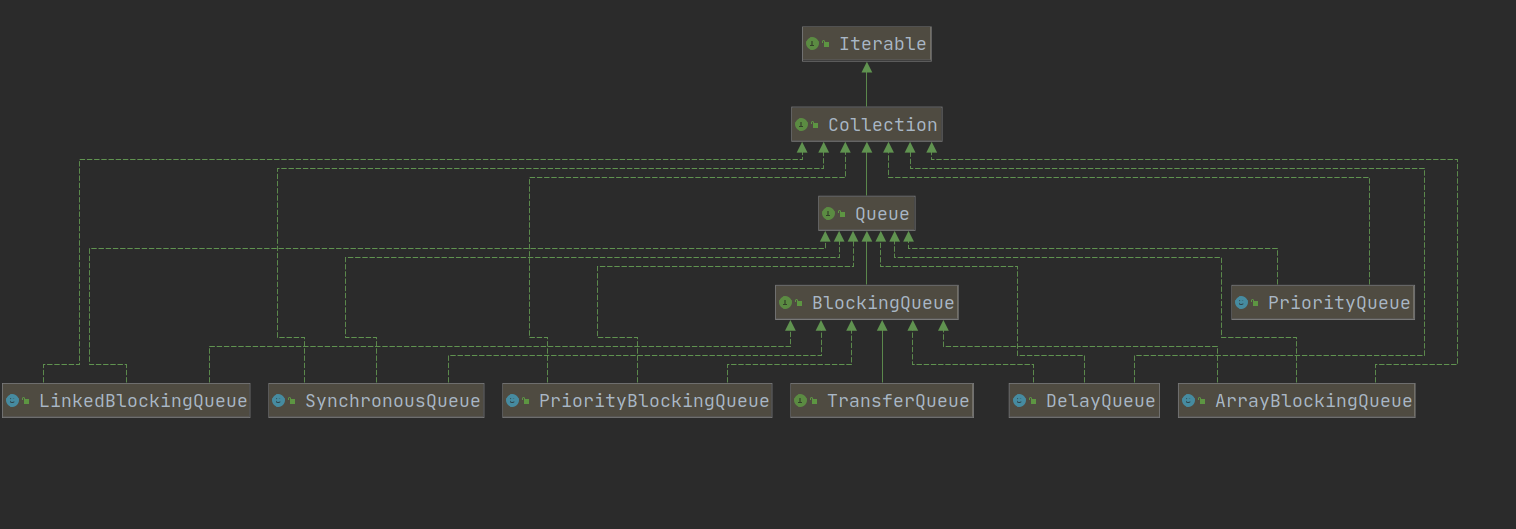
Queue有更多灵活的api,为多线程带来更友好的选择:
LinkedQueue是无界的,ArrayQueue是无界的。
offer满了返回falseput满了阻塞add满了抛异常cleartake阻塞
线程池#
Callable、Future等基础#
Callable#
Callable是一个和Runnable类似,只有一个带返回值的V callable()方法。而传统的Runnable的run()是没有返回值的。
Future:#
一个获取线程返回值的接口
- cancel
- get
- get(time)
- isCancelled
- isDone
FutureTask更灵活的选择#
可以理解为同时实现了Runnable和Future接口,既是一个运行者,也存储运行结果。
- 既然实现了
Runnable接口,就可以传入Thread中运行 - 既然实现了
Future接口,就可以获取运行返回值 - 在后面的WorkStealingPool和ForkJoinPool中有大量应用
1 | /** |
CompletableFuture 非常灵活#
可以用来管理多个Future的运行过程和运行结果。提供了对一堆任务的管理,比如需要N个任务同时完成join才能继续。
可以避免各种if等。
1 | // 声明三个CompletableFuture |
线程池#
分为ForkJoinPool和ThreadPoolExecutor两大类。
-
ThreadPoolExecutor普通线程池 -
ForkJoinPool是任务分解的线程池
Executors#
执行器接口,可以允许我们把线程的定义和运行分开。
-
Executors里面提供了很多创建线程池的方法,包括一下方法:-
以下方法都是有问题的,不建议直接使用!需要使用手动7个参数方式创建
-
newFixedThreadPool(int nThreads):最大最小线程数量相等,可以并行
-
new ThreadPoolExecutor(nThreads, nThreads, // 线程数固定 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); // 任务太多,OOM <!--code2-->
-
-
ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) // 线程数可能巨多,OOM
-
new ThreadPoolExecutor(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); // 使用了一个DelayedWorkQueue来完成调度 <!--code3--> -
ScheduledExecutorService newSingleThreadScheduledExecutor()
-
newWorkStealingPool(int parallelism) --------------1.8新增的工作窃取线程池
-
上面的线程池在并发大的时候就会有问题,比如FixedThreadPool会堆积任务、CachedThreadPool会堆积线程
ExecutorService#
ExecutorService里面定义了线程池的生命周期:- submit(Callable
task); - submit(Runnable task);
- submit(Runnable task, T result);
- shutdown();
- boolean isShutdown();
List<Future > invokeAll(Collection<? extends Callable > tasks) 给一堆任务,返回一堆Future
- submit(Callable
默认线程数设置#
-
经验值+压力测试。
-
一个经验公式如下:
- N是Cpu核心数量,
- U是比如期望当前线程池程序占用CPU用到50%就是0.5(还有其他线程池在运行)
- W/C是等待时间和计算时间的壁纸。在几乎无IO的场景这个值趋近于0,在IO很多wait很多的场景很大。这个值很难估算。
-
还是需要压力测试,调整。

如果CPU密集型,可以CPU核数+1,期望最高100%.
何时用CachedPool何时用FixPool#
- Cache是任务不平稳时候采用,可以波谷节省资源
- FixPool是任务数量产生平稳,没什么太大波动的时候采用,节省创建开销
自定义线程池 new ThreadPoolExecutor#
自定义创建线程池的必要性#
不允许自行手动new Thread,而是使用线程池:
- 这样可以减少线程创建和销毁开销,以及资源不足开销。否则容易造成过度创建线程,切换过度的问题。
不能使用Executors去创建内置线程池,要使用ThreadPoolExecutor创建。
-
Executors 返回的线程池对象的弊端如下:
- 1) FixedThreadPool 和 SingleThreadPool:
- 使用了LinkedBlockingQueue,允许的请求任务队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
- 2) CachedThreadPool:
- 允许的创建线程数量为 Integer.MAX_VALUE, 可能会创建大量的线程,从而导致 OOM
- 1) FixedThreadPool 和 SingleThreadPool:
自定义线程池的7个参数#
1 | public ThreadPoolExecutor(int corePoolSize, // 核心线程数 |
任务队列BlokingQueue#
- 各种阻塞队列去做任务队列。
- ArrayBlockingQueue是有界的,
- LinkedBlockingQueue最大是Integer.MaxValue
- TransferQueue 1长度
- SynchousQueue 0长度
线程工厂ThreadFactory#
// 根据runnable去产生thread的工厂。
// 默认这个threadFactory里面产生线程指定了group、线程名(前缀+增量整数)、指定不是守护线程、普通优先级。
Executors.defaultThreadFactory(),
阿里推荐类似这样创建线程工厂
1 | public class UserThreadFactory implements ThreadFactory { |
拒绝策略#
当线程池到达最大线程数,且任务队列满的时候执行的操作(或者线程池已经关闭也会执行)。默认有四种,但是生产都不用。
-
接口 RejectedExecutionHandler 决绝执行拦截器,只有一个方法
void rejectedExecution(Runnable r, ThreadPoolExecutor executor),被ThreadPoolExecutor在任务队列也满了的时候执行。 -
DiscardPolicy() 啥也没干的空实现,悄悄丢掉当前任务
-
ThreadPoolExecutor.DiscardOldestPolicy(); ------丢弃掉最老的,游戏服务丢掉最老的位置信息。
-
AbortPolicy() 抛了一个异常,调用者去处理异常。-----------------------默认策略,抛出RejectedExecutionException
-
CallerRunsPolicy(),当前调用者来运行(谁提交的任务,就谁来运行)
-
一般生产上面的一个都不用,自定义,将在RejectedExecutionHandler的实现策略中将任务保存在kafka、redis、mq、数据库中,并打印日志,以备后续再来读取执行。
-
然后考虑调节线程大小、任务队列大小。再不行的话就要加机器。
ThreadPoolExecutor源码#
- 内部使用了一个原子的int来保存控制状态
AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));- 前3位是状态,后面29位是线程数量。
- 使用一个int去存放两个值可以减少加锁次数。
主要基础成员变量#
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
构造方法#
七个参数,见上一节
1 | public ThreadPoolExecutor(int corePoolSize, |
执行任务execute方法#
1 | public void execute(Runnable command) { |
添加任务addWorker源码#
使用了两层自旋锁,外层去把worker的数量+1
内层添加到worker中
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
运行任务,Worker的run方法委托来的#
1 | final void runWorker(Worker w) { |
内部类Worker的源码(继承了AQS、实现Runnable)#
- Worker继承了 AQS,说明 Worker 本身是个锁,而且在tryAcquire以及其他对AQS方法的实现,都说明了它不支持重入。因为参数都写死为1,如果是重入功能的锁的话,会支持累加。(而且实现都是很简单的CAS修改一个state)
- 因为很多个任务都要等着往Worker提交,所以需要AQS来支持同步,自身变成一个锁。
- 实现了Runnable,把run方法委托给外面线程池ExecutorService的runWorker(w)去执行
1 | private final class Worker |
WorkStealingPool/ForkJoinPool#
先看一眼类图的关系:

常规的ThreadPoolExe
创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask
当任务完成后会去其他线程的任务队列中窃取任务回来执行。
- ForkJoinPool是适合把大任务切分为小任务的线程池。可以支持把一个任务拆分到很多线程中执行,执行完还可以汇总结果。
push和pop不用锁,poll偷的时候需要锁。

Fork/Join线程池#
- 抽象类
ForkJoinTask是核心类,这个类实现了Future,可以获取值 RecursiveTask<V>是ForkJoinTask的一个子类,带返回参数。- 还有一个类似的
RecursiveAction是没有返回值的,只划分子任务运行,不返回RecursiveAction。 - 都需要定义一个构造方法(setter也行),去设置当前任务所需的参数
- 都是需要重写compute()方法,并分解当前任务的参数到子任务中,然后获取子任务的值。
- 创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask
task) 或invoke(ForkJoinTask task)方法来执行指定任务了。前者异步future,后者同步。
两个主要方法:
- fork()
fork()方法类似于线程的Thread.start()方法,但是它不是真的启动一个线程,而是将任务放入到工作队列中。
- join()
join()方法类似于线程的Thread.join()方法,但是它不是简单地阻塞线程,而是利用工作线程运行其它任务。当一个工作线程中调用了join()方法,它将处理其它任务,直到注意到目标子任务已经完成了。
详细分析:
- 它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
- ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。
- 这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。
- 比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
- 那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
- 所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
- 以上程序的关键是fork()和join()方法。在ForkJoinPool使用的线程中,会使用一个内部队列来对需要执行的任务以及子任务进行操作来保证它们的执行顺序。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
- 首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。
- 但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
ps:ForkJoinPool在执行过程中,会创建大量的子任务,导致GC进行垃圾回收,这些是需要注意的。
第一个例子,Fibonacci数列#
1 | /** |
另一个例子,求[a,b]区间所有整数的sum#
1 | /** |
经典面试题QA#
-
加入提供了一个闹钟服务,比如7:00叫醒,订阅的人很多如10亿。如何优化?
-
并行parallel和并发concurrent:
- 并发是任务提交,(如很多任务同时涌过来)
- 并行是任务执行。(如多个任务真的在多核同时处理)
- 并行是并发的子集。
基准测试工具JMH#
Java Micro-Benchmark
注意事项#
- ThreadLocal 变量必须在finally中remove。