文章主线:
CAS---->Unsafe---->CAS底层实现和思想---->ABA问题---->原子引用更新---->如何规避ABA问题
这篇博客还不错
背景#
- 在以前没有CAS的时候,对一个多线程修改i++是有线程安全问题的,因为
i++操作底层是三个指令,不是原子的。 - 使用AtomicInteger替代Integer即可线程安全。AtomicInteger底层就是CAS支持的。
CAS简介#
- CompareAndSet,比较并交换思想,底层是CPU并发源语言。功能是判断某个内存是为是否是预期的值,true则更新,false放弃。过程是原子的(线程安全)。
- CAS是一种轻量级锁,在没有线程阻塞的情况下实现变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁(读多场景被修改后重试或者报错)。
- 是一种乐观锁思想,通过自旋进行无锁优化。
- CPU原语音硬件实现,执行必须连续,所以天生就是原子的。线程安全。
- 底层通过
Unsafe类实现,Unsafe中的CAS方法JVM会生成汇编指令。

Atomic修饰的类为啥是线程安全的?如AtomicInteger#
AtomicInteger.java的getAndIncrement方法,获取值并+1,底层借助了JDK的rt.jar中的unsafe类的native方法。- unsafe类是
sun.misc.Unsafe,使用本地方法帮Java操纵底层。如读写操纵特定内存位置的数据。----直接操纵操作系统执行任务 - 下面代码里直接用unsafe去操纵内存偏移位置上的对象,是不允许中断的连续的指令,是线程安全的,所以没有并发问题。
- 变量value使用volatile修饰,保证多线程的可见性
AtomicInteger.java 节选:
1 | private volatile int value; // 当前AtomicInteger内部使用了一个volatile修饰的int存储值。 |
unsafe.java底层实现:#
使用了compareAndSwapInt自旋:
1 | // unsafe类的 getAndAddInt 方法 |
var5:就是我们从主内存volatile中拷贝到工作内存中的值操作的时候,需要比较工作内存中的值,和主内存中的值进行比较
假设执行 compareAndSwapInt返回false,那么就一直执行 while方法,直到期望的值和真实值一样
- val1:AtomicInteger对象本身
- var2:该对象值的引用内存地址
- var4:需要修改变动的数量
- var5:用var1和var2找到的内存中的真实值
- 用该对象当前的值与var5比较
- 如果相同,更新var5 + var4 并返回true,结束循环。
- 如果不同,继续取volatile值然后再比较,直到更新完成
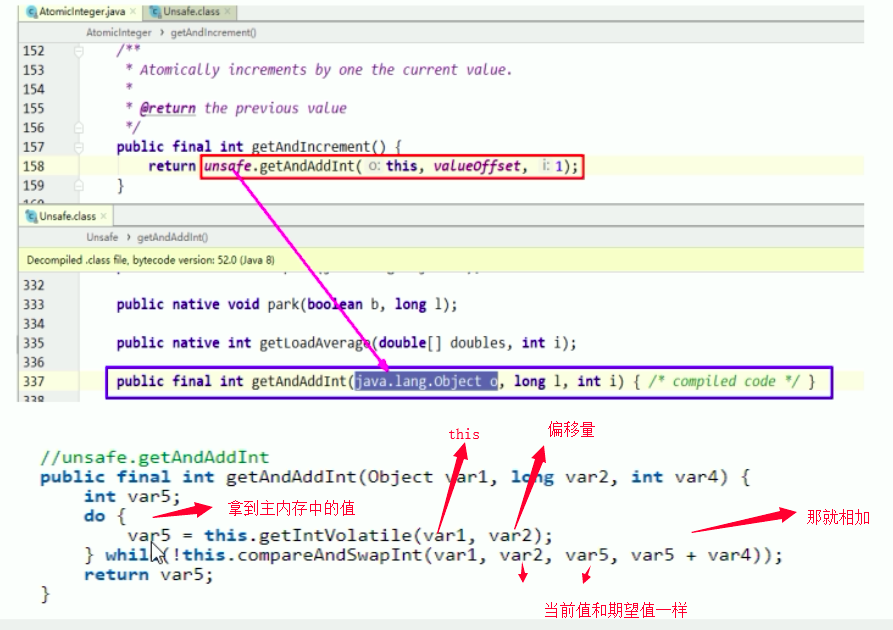
这里没有用synchronized,而用CAS,这样提高了并发性,也能够实现一致性,是因为每个线程进来后,进入的do while循环,然后不断的获取内存中的值,判断是否为最新,然后在进行更新操作。
假设线程A和线程B同时执行getAndAddInt操作(分别跑在不同的CPU上)
- AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的 value 为3,根据JMM模型,线程A和线程B各自持有一份价值为3的副本,分别存储在各自的工作内存
- 线程A通过getIntVolatile(var1 , var2) 拿到value值3,这是线程A被挂起(该线程失去CPU执行权)
- 线程B也通过getIntVolatile(var1, var2)方法获取到value值也是3,此时刚好线程B没有被挂起,并执行了compareAndSwapInt方法,比较内存的值也是3,成功修改内存值为4,线程B打完收工,一切OK
- 这是线程A恢复,执行CAS方法,比较发现自己手里的数字3和主内存中的数字4不一致,说明该值已经被其它线程抢先一步修改过了,那么A线程本次修改失败,只能够重新读取后在来一遍了,也就是在执行do while
- 线程A重新获取value值,因为变量value被volatile修饰,所以其它线程对它的修改,线程A总能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。
compareAndSwapInt的底层CPU源语实现—lock cmpxchg:#
汇编语言cmpxchg指令,也是compareAndSwapInt的实现。

多核情况下最终的实现:lock cmpxchg
- lock指令是锁总线,所以
lock cmpxchg

Unsafe类 + CAS思想: 也就是自旋,自我旋转
CAS这里不需要经过操作系统的线程管理,所以是轻量级的,synchronized是需要操作系统进行线程管理是总量级的。
CAS缺点#
和synchronized比较,没有加锁每个线程都可以同时竞争并发计算,但是也有以下缺点:
- 循环太多的时候,自旋太多。do…while太多,CPU开销大。(没有锁,需要大量比较)
- 只能保证一个变量的原子性,不像synchronized可以对多个变量进行原子性操作。
- 引出了ABA问题,两个线程在执行CAS竞争的时候,一个线程T1很慢,另一个T2很快。初始的时候快照变量都是A,在拿到线程内存中后,T2修改为B并CAS写回成功。然后T2再来一次CAS把变量从B改为A,后来T1才回来,一看主内存还是A,CAS成功改成C。但这时候的A和刚才的A虽然值一样,但是可能业务发生了变化。造成问题。具体见下一章。
小结#
CAS应用#
CAS是compareAndSwap,比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否者继续比较直到主内存和工作内存的值一致为止。
CAS有3个操作数,内存值V,旧的预期值A,要修改的更新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否者什么都不做。
适用于在写少读多的时候,使用CAS完成单变量的同步。
ABA问题是什么?原子更新引用是什么?#
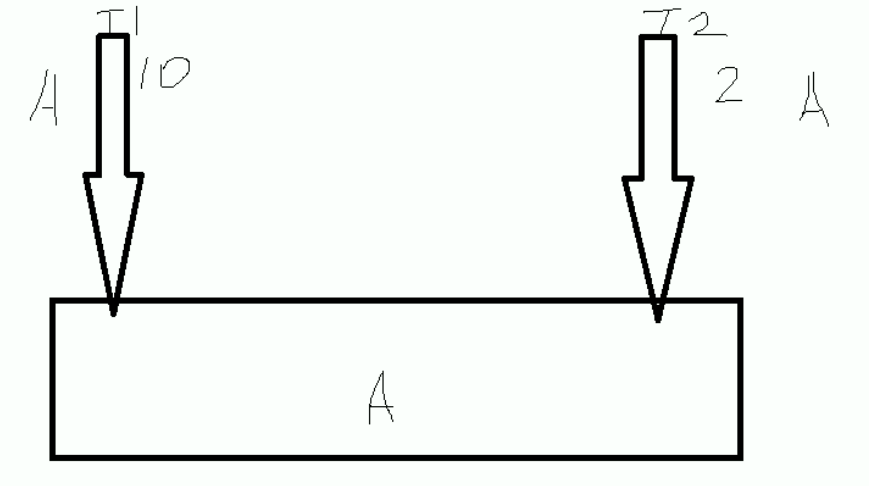
假设现在有两个线程,分别是T1 和 T2,然后T1执行某个操作的时间为10秒,T2执行某个时间的操作是2秒,最开始AB两个线程,分别从主内存中获取A值,但是因为B的执行速度更快,他先把A的值改成B,然后在修改成A,然后执行完毕,T1线程在10秒后,执行完毕,判断内存中的值为A,并且和自己预期的值一样,它就认为没有人更改了主内存中的值,就快乐的修改成B,但是实际上 可能中间经历了 ABCDEFA 这个变换,也就是中间的值经历了狸猫换太子。
所以ABA问题就是:在获取主内存值的时候,该内存值在我们写入主内存的时候,已经被修改了N次,但是最终又改成原来的值了
CAS导致ABA问题#
CAS算法实现了一个重要的前提,需要取出内存中某时刻的数据,并在当下时刻比较并替换,那么这个时间差会导致数据的变化。
比如说一个线程one从内存位置V中取出A,这时候另外一个线程two也从内存中取出A,并且线程two进行了一些操作将值变成了B,然后线程two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后线程one操作成功
尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的,看业务情况。
ABA问题#
如果业务只管最终的数值是无所谓的,最终都是A即可。ABA问题就可以接受。(只看结果)
但是如果业务要求中间不能被别的线程偷偷改变还不知道(如支付类)。ABA问题就无法被接受。(要求过程)
可以用版本或者标签解决ABA问题,也可以用AtomicStampedReference
原子引用AtomicReference#
原子引用其实和原子包装类是差不多的概念,就是将一个java类,用原子引用类进行包装起来,那么这个类就具备了原子性。可以完成类似AtomicInteger等同样的原子性效力。
但是原子引用打来了ABA问题。
带版本的原子引用解决ABA问题 AtomicStampedReference#
通过一个版本号stamp来解决ABA问题,内同一致但是版本号不一致还是不能提交修改。
1 | package com.sam.phoenix.concurrent; |
LongAdder(CAS机制优化)#
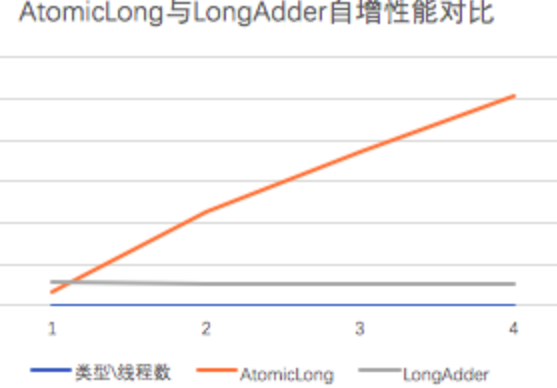
LongAdder是java8在atomic包里为我们提供的新的类,跟AtomicLong有相同的效果。是对CAS机制的优化
类似的还有一个DoubleAdder:
1 | LongAdder: |
为什么有了AtomicLong还要新增一个LongAdder呢#
原因是:CAS底层实现是在一个死循环中不断地尝试修改目标值,直到修改成功。如果竞争不激烈的时候,修改成功率很高,否则失败率很高。在失败的时候,这些重复的原子性操作会耗费性能。(不停的自旋,进入一个无限重复的循环中)
核心思想:将热点数据分离。
比如说它可以将AtomicLong内部的内部核心数据value分离成一个数组,每个线程访问时,通过hash等算法映射到其中一个数字进行计数,而最终的计数结果则为这个数组的求和累加,其中热点数据value会被分离成多个单元的cell,每个cell独自维护内部的值。当前对象的实际值由所有的cell累计合成,这样热点就进行了有效地分离,并提高了并行度。这相当于将AtomicLong的单点的更新压力分担到各个节点上。在低并发的时候通过对base的直接更新,可以保障和AtomicLong的性能基本一致。而在高并发的时候通过分散提高了性能。
1 | public void increment() { |
CAS有没有问题呢?肯定是有的。比如说大量的线程同时并发修改一个AtomicInteger,可能有很多线程会不停的自旋,进入一个无限重复的循环中。
这些线程不停地获取值,然后发起CAS操作,但是发现这个值被别人改过了,于是再次进入下一个循环,获取值,发起CAS操作又失败了,再次进入下一个循环。
在大量线程高并发更新AtomicInteger的时候,这种问题可能会比较明显,导致大量线程空循环,自旋转,性能和效率都不是特别好。
于是,当当当当,Java 8推出了一个新的类,LongAdder,他就是尝试使用分段CAS以及自动分段迁移的方式来大幅度提升多线程高并发执行CAS操作的性能!
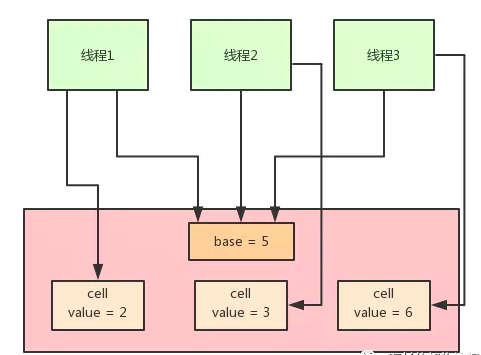
在LongAdder的底层实现中,首先有一个base值,刚开始多线程来不停的累加数值,都是对base进行累加的,比如刚开始累加成了base = 5。
接着如果发现并发更新的线程数量过多,在发生竞争的情况下,会有一个Cell数组用于将不同线程的操作离散到不同的节点上去 ==(会根据需要扩容,最大为CPU核)==就会开始施行分段CAS的机制,也就是内部会搞一个Cell数组,每个数组是一个数值分段。
这时,让大量的线程分别去对不同Cell内部的value值进行CAS累加操作,这样就把CAS计算压力分散到了不同的Cell分段数值中了!
这样就可以大幅度的降低多线程并发更新同一个数值时出现的无限循环的问题,大幅度提升了多线程并发更新数值的性能和效率!
而且他内部实现了自动分段迁移的机制,也就是如果某个Cell的value执行CAS失败了,那么就会自动去找另外一个Cell分段内的value值进行CAS操作。
这样也解决了线程空旋转、自旋不停等待执行CAS操作的问题,让一个线程过来执行CAS时可以尽快的完成这个操作。
最后,如果你要从LongAdder中获取当前累加的总值,就会把base值和所有Cell分段数值加起来返回给你。
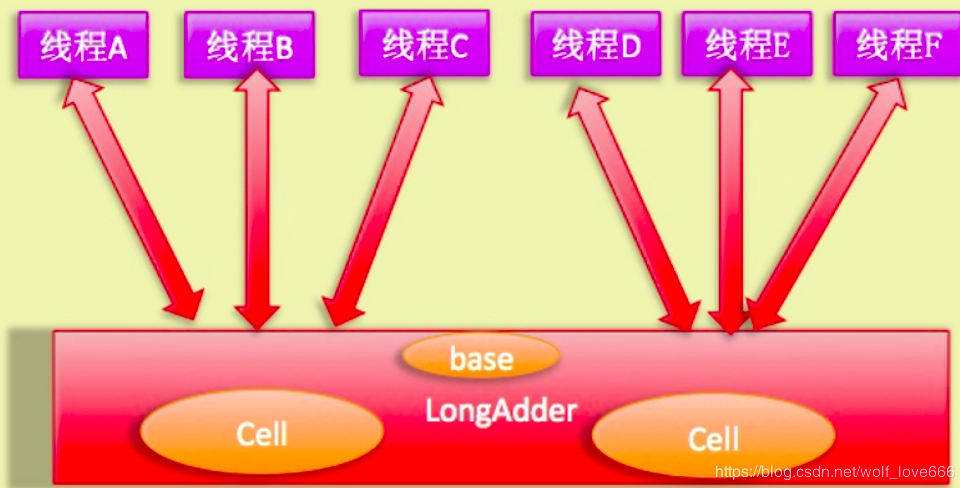
如上图所示,LongAdder则是内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同一个原子变量时候,
如果失败并不是自旋CAS重试,而是尝试获取其他原子变量的锁,最后当获取当前值时候是把所有变量的值累加后再加上base的值返回的。
LongAdder维护了要给延迟初始化的原子性更新数组和一个基值变量base数组的大小保持是2的N次方大小,数组表的下标使用每个线程的hashcode值的掩码表示,数组里面的变量实体是Cell类型。
Cell 类型是Atomic的一个改进,用来减少缓存的争用,对于大多数原子操作字节填充是浪费的,因为原子操作都是无规律的分散在内存中进行的,多个原子性操作彼此之间是没有接触的,但是原子性数组元素彼此相邻存放将能经常共享缓存行,也就是伪共享。所以这在性能上是一个提升。(补充:可以看到Cell类用Contended注解修饰,这里主要是解决false sharing(伪共享的问题),不过个人认为伪共享翻译的不是很好,或者应该是错误的共享,比如两个volatile变量被分配到了同一个缓存行,但是这两个的更新在高并发下会竞争,比如线程A去更新变量a,线程B去更新变量b,但是这两个变量被分配到了同一个缓存行,因此会造成每个线程都去争抢缓存行的所有权,例如A获取了所有权然后执行更新这时由于volatile的语义会造成其刷新到主存,但是由于变量b也被缓存到同一个缓存行,因此就会造成cache miss,这样就会造成极大的性能损失)
LongAdder的add操作图
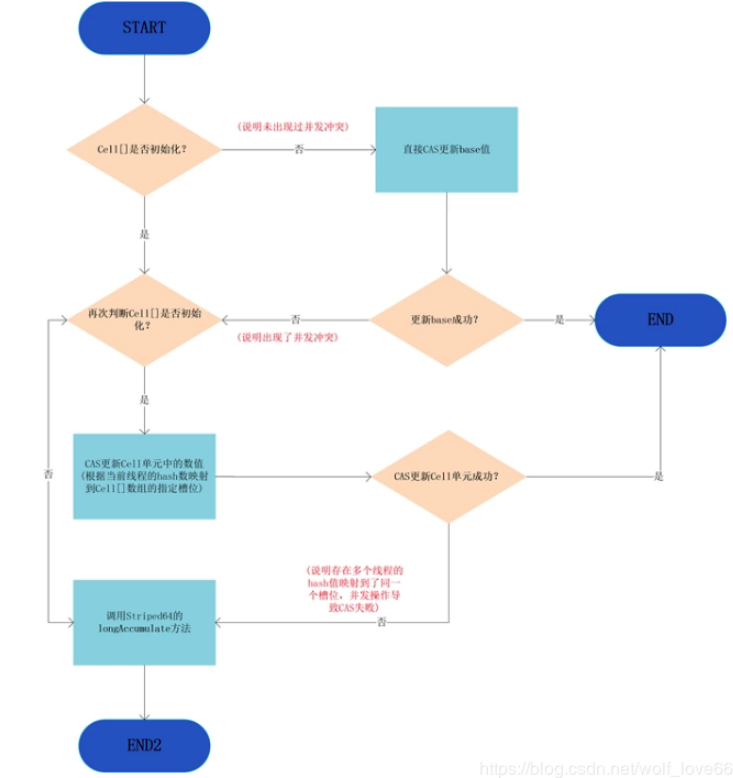
可以看到,只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对Cell[]数组中的单元Cell。
如果Cell[]数组未初始化,会调用父类的longAccumelate去初始化Cell[],如果Cell[]已经初始化但是冲突发生在Cell单元内,则也调用父类的longAccumelate,此时可能就需要对Cell[]扩容了。
另外由于Cells占用内存是相对比较大的,所以一开始并不创建,而是在需要时候再创建,也就是惰性加载,当一开始没有空间时候,所有的更新都是操作base变量。
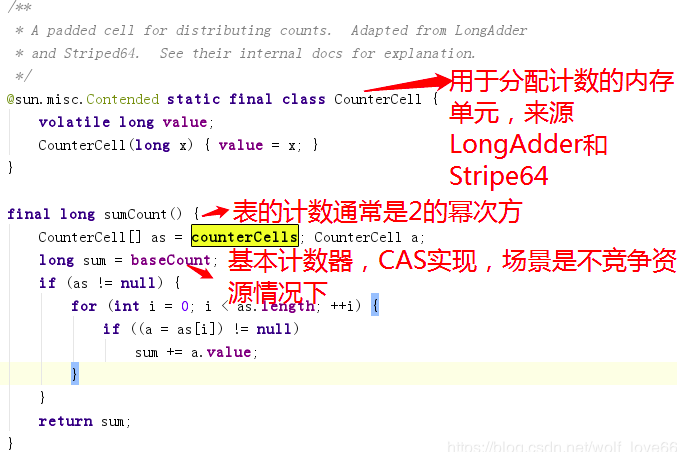
如上图代码:
例如32、64位操作系统的缓存行大小不一样,因此JAVA8中就增加了一个注@sun.misc.Contended解用于解决这个问题,由JVM去插入这些变量,具体可以参考openjdk.java.net/jeps/142 ,但是通常来说对象是不规则的分配到内存中的,但是数组由于是连续的内存,因此可能会共享缓存行,因此这里加一个Contended注解以防cells数组发生伪共享的情况。
为了降低高并发下多线程对一个变量CAS争夺失败后大量线程会自旋而造成降低并发性能问题,LongAdder内部通过根据并发请求量来维护多个Cell元素(一个动态的Cell数组)来分担对单个变量进行争夺资源。

可以看到LongAdder继承自Striped64类,Striped64内部维护着三个变量,LongAdder的真实值其实就是base的值与Cell数组里面所有Cell元素值的累加,base是个基础值,默认是0,cellBusy用来实现自旋锁,当创建Cell元素或者扩容Cell数组时候用来进行线程间的同步。
在无竞争下直接更新base,类似AtomicLong高并发下,会将每个线程的操作hash到不同的cells数组中,从而将AtomicLong中更新一个value的行为优化之后,分散到多个value中
从而降低更新热点,而需要得到当前值的时候,直接 将所有cell中的value与base相加即可,但是跟AtomicLong(compare and change -> xadd)的CAS不同,incrementAndGet操作及其变种可以返回更新后的值,而LongAdder返回的是void。
由于Cell相对来说比较占内存,因此这里采用懒加载的方式,在无竞争的情况下直接更新base域,在第一次发生竞争的时候(CAS失败)就会创建一个大小为2的cells数组,每次扩容都是加倍,只到达到CPU核数。同时我们知道扩容数组等行为需要只能有一个线程同时执行,因此需要一个锁,这里通过CAS更新cellsBusy来实现一个简单的spin lock。
数组访问索引是通过Thread里的threadLocalRandomProbe域取模实现的,这个域是ThreadLocalRandom更新的,cells的数组大小被限制为CPU的核数,因为即使有超过核数个线程去更新,但是每个线程也只会和一个CPU绑定,更新的时候顶多会有cpu核数个线程,因此我们只需要通过hash将不同线程的更新行为离散到不同的slot即可。
我们知道线程、线程池会被关闭或销毁,这个时候可能这个线程之前占用的slot就会变成没人用的,但我们也不能清除掉,因为一般web应用都是长时间运行的,线程通常也会动态创建、销毁,很可能一段时间后又会被其他线程占用,而对于短时间运行的,例如单元测试,清除掉有啥意义呢?