网络基础#
先复习一下大一的计算机基础,OSI七层参考模型和TCP五层协议
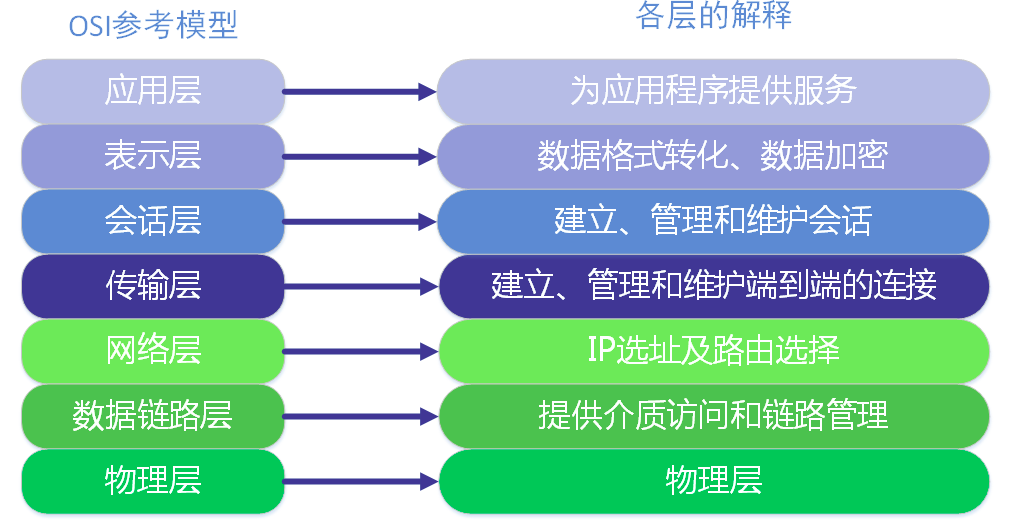
OSI七层模型#
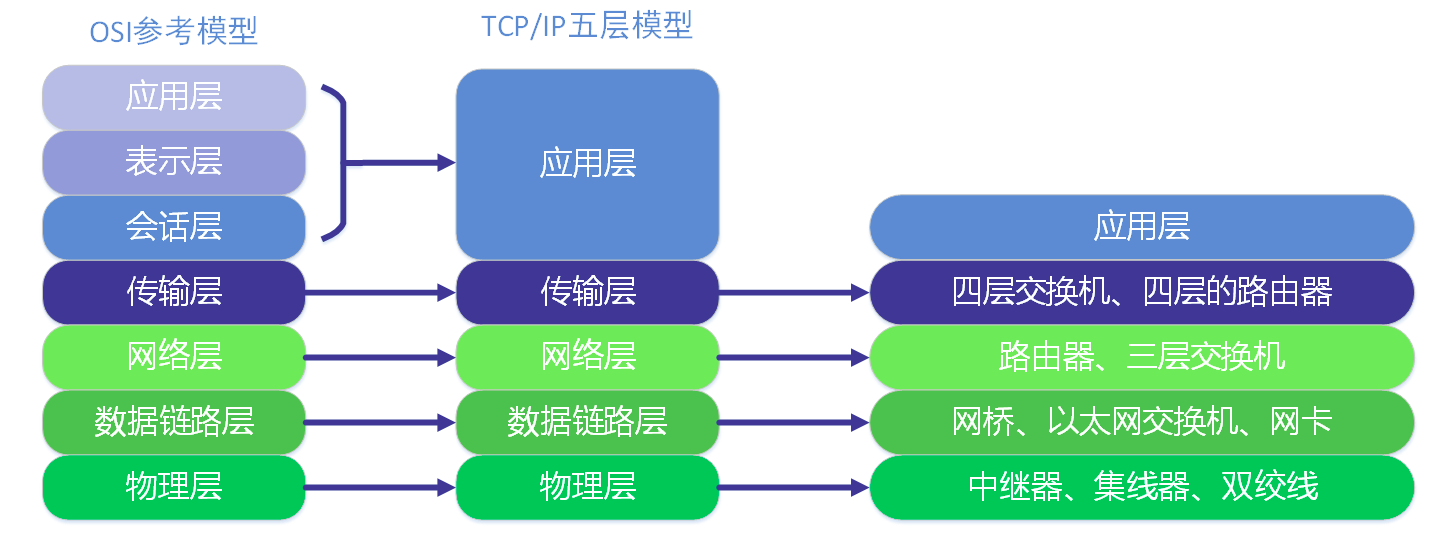
TCP五层模型#
OSI的七层里面,表示层是说格式、安全、压缩,如JPEG、ASCll、加密方式。会话层是用来控制连接的建立、管理和断开。
这两层和原始的应用层在TCP/IP协议中被统一到了的应用层。
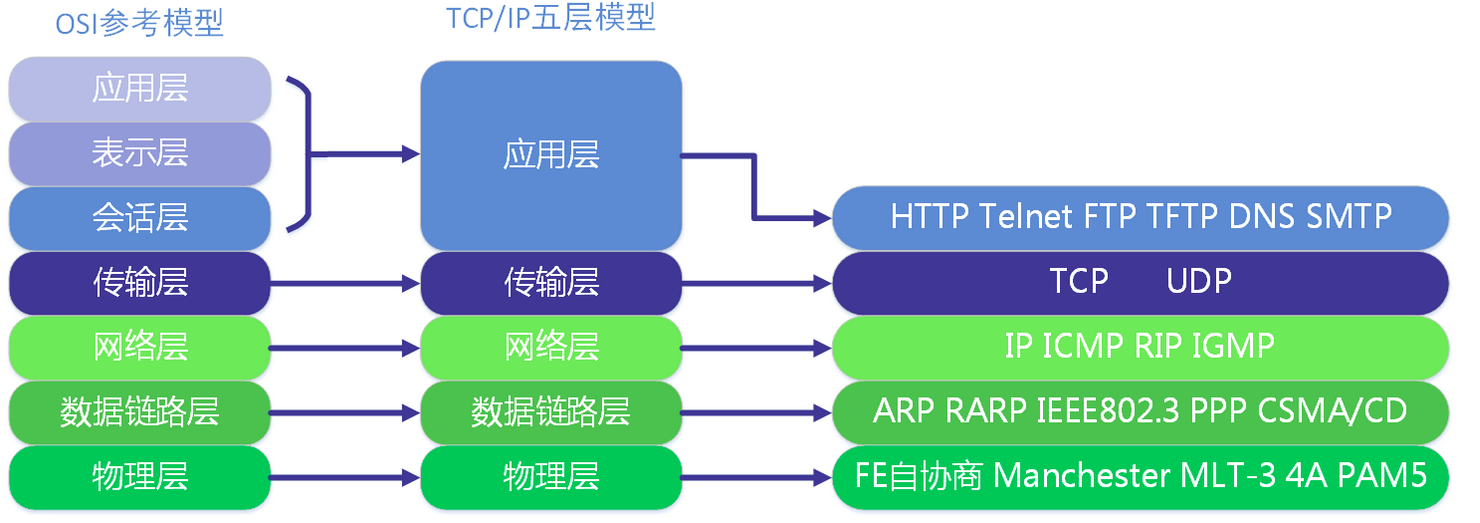
TCP/IP协议的每一层常见协议:
TCP/IP通讯基础原理#
OSI基础模型#
提到IO,首先是OSI参考模型,计算机网络基础,一共七层
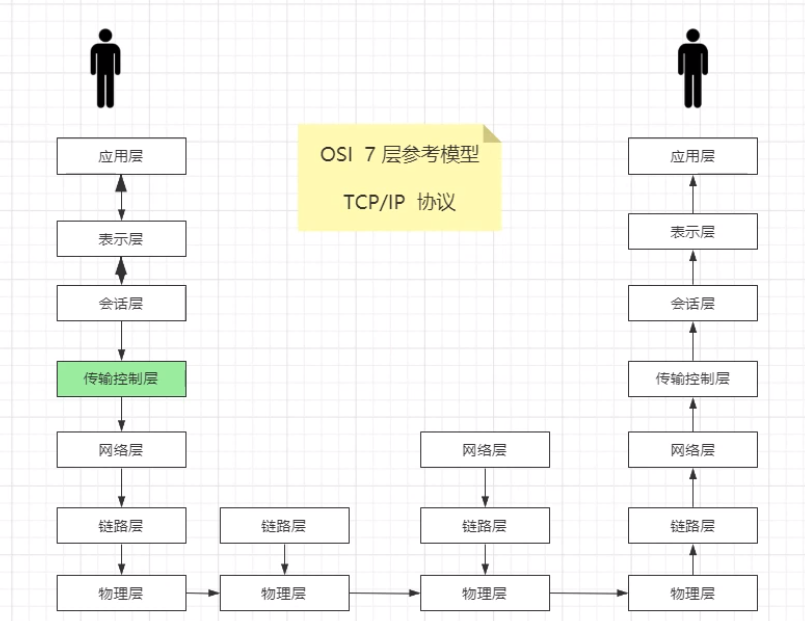
这7层是一个虚的东西,是一个规范。TCP/IP协议给精简到4层,把上面的应用层-表示层-会话层统一归结到新的应用层是用户称,把下面的传输控制层-网络层-链路层-物理层视为内核层。
| OSI七层网络模型 | TCP/IP四层概念模型 | 对应网络协议 |
|---|---|---|
| 应用层(Application) | 应 | HTTP、TFTP, FTP, NFS, WAIS、SMTP |
| 表示层(Presentation) | 用 | Telnet, Rlogin, SNMP, Gopher |
| 会话层(Session) | 层 | SMTP, DNS |
| 传输层(Transport) | 传输层 | TCP, UDP |
| 网络层(Network) | 网络层 | IP, ICMP, ARP, RARP, AKP, UUCP |
| 数据链路层(Data Link) | 数据 | FDDI, Ethernet, Arpanet, PDN, SLIP, PPP |
| 物理层(Physical) | 链路层 | IEEE 802.1A, IEEE 802.2到IEEE 802.11 |
TCP/IP通讯过程#
网络概述#
- 假设红色的计算机1是
192.168.1.4,子网掩码是255.255.255.0处于192.168.1.0这个子网。路由器网关是192.168.1.1. - 另一个机器4是
192.168.3.4,子网掩码是255.255.255.0处于192.168.3.0这个子网,路由器网关是192.168.3.1。 - 路由器有两个网卡,一个是
192.168.1.1,另一个网卡ip是192.168.3.1,连接到两个网络上

初始路由#
初始的时候计算机1的路由表至少有2条:
路由表和子网掩码做一次按位与运算,就能找到下一跳。至少有两个路由route -n:
| 目标 | 网关 | 子网掩码 | 使用 接口 | 说明 |
|---|---|---|---|---|
| 192.168.1.0 | 0.0.0.0 | 255.255.255.0 | eth0 | # 任何192.168.1.x的请求和255.255.255.0按位与之后都是192.168.1.0,匹配上,然后因为是0.0.0.0,说明在一个子网,直接发给eth0去处理。 |
| 0.0.0.0 | 192.168.1.1 | 0.0.0.0 | eth0 | # 其他任何请求和0.0.0.0按位与之后都是0.0.0.0,匹配上,就会发送到 |
- 上面第一行网关里面
0.0.0.0被称为默认网关,只有一个。代表和前面的目标是同一局域网,不需要下一跳转发,直接请求。 - 如果网关不是
0.0.0.0,就说明不是直连的,需要下一跳才能访问。
计算机3对应的有两个路由:
| 目标 | 网关 | 子网掩码 | 使用 接口 |
|---|---|---|---|
| 192.168.3.0 | 0.0.0.0 | 255.255.255.0 | eth0 |
| 0.0.0.0 | 192.168.3.1 | 0.0.0.0 | eth0 |
此时记住路由器有两个网卡,一个是192.168.1.1,另一个网卡ip是192.168.3.1
数据包封装#
- 此时计算机1请求计算机3,发送的数据包,ip是计算机3的192.168.3.4,端口8080,但是计算机1不知道计算机3在哪里,只能通过路由表192.168.3.4和0.0.0.0按位与,结果是0.0.0.0和第二条匹配,就走下一跳的网关192.168.1.1
- 数据包上面会写上下一跳192.168.1.1的MAC地址,表示我要去下一跳是这里。
ARP协议#
arp协议用于完成ip和mac的映射。
初始的时候,计算机1和计算机3都不知道网络中其他机器的MAC,这时候arp协议就上场了。arp
| 地址 | 类型 | 硬件 | 接口 |
|---|---|---|---|
| 192.168.x.x | ether | 00:12:32:16:14:23 | eth0 |
刚开机的时候arp里面是空的,网络激活的时候,arp发送mac为全FF:FF:FF的广播,目标ip是网关192.168.1.1,源ip是1.4。交换机会给广播到所有的节点。只有目标的网关会响应。会回复给计算机1,也就是1.4自己的mac。此时计算机1就有了一条记录。
同时交换机也会学习记录mac信息,回去的时候会成功返回给1.1。
数据包封装2#
经过上面的arp协议,现在计算机1可以把目标ip为192.168.3.4,mac是下一跳是192.168.1.1的包发出去了。
1.1的网关接收到之后,继续在路由里面匹配,然后只修改包里面的mac,继续往下一跳走。
如此往复就完成了数据包的传递。
结论#
- TCP/IP是一个基于下一跳机制的传输协议
- IP是两个端点,发送方和接收方。
- mac地址是节点之间,下一跳的信息。
- 端口是对应接收方的一个进程
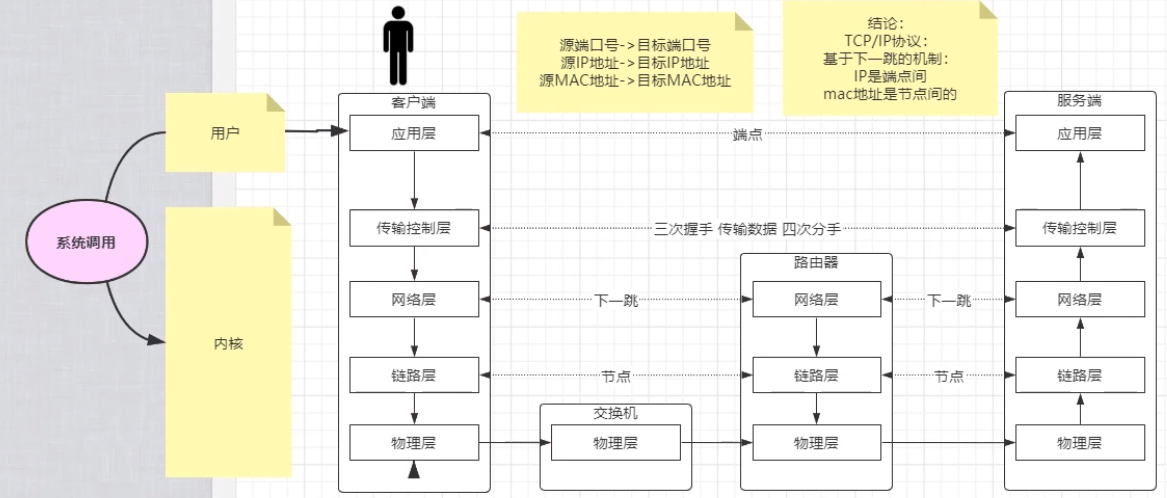
流程回顾#
-
上层的应用无论是http请求还是ftp还是ssh等等,想请求需要先向底层传输控制层去获取一个socket。
-
假如是tcp的,需要三次握手。下层的传输控制层先去构建一个握手包,握手包通过下层的网络层通过路由下一跳的方式发出去。
-
下一跳怎么发出去呢?链路层的arp协议获取了下一跳的mac地址,重新包装握手包,通过物理层发出去。
数据包包括:
-
源端口号,目标端口号(代表进程)
-
源IP地址,目标IP地址(决定端点)
-
源Mac地址,和目标Mac地址(决定下一跳找哪个服务器),每跳一次,源mac地址和目标mac地址都会改变。但是源和目标ip不变。
-
以上三点就可以决定从源到目标的数据包发送
linux命令测试讲解TCP#
创建一个到baidu的文件描述符(内核层)#
- linux一切皆文件,每一个程序都有自己的IO流。程序里面的IO流也会被描述成文件(数字)。没一个程序都有3个自带的文件描述符:
- 0:system.in
- 1: system.out
- 2: system.err
- 用户创建的IO就从3开始
**【举例】**执行一个bash命令创建一个到baidu的socket,IO流重定向到当前进程的8号文件描述符中:
-
exec 8<> /dev/tcp/www.baidu.com/80 -
上面面创建了一个文件描述符“8”,是一个socket指向了百度,
-
8是文件描述符fd(就像代码的变量),<>是一个双向输入输出流,可以看到
-
echo $$ # 打印当前命令行的进程号 16199 # 也可以ps -ef 然后grep出来 tree 16199 9368 0 4月15 pts/1 00:00:01 /bin/bash1
2
3
4
5
6
7
8
9
10
11
12
- 可以去当前进程的目录看一眼
- ```bash
cd /proc/16199/fd # 进入当前进程的fd目录
ls # 看一眼
lrwx------ 1 tree tree 64 5月 21 18:31 0 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 1 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 2 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 255 -> /dev/pts/1
lrwx------ 1 tree tree 64 5月 21 18:31 8 -> 'socket:[1037956]'
# 每个进程都有0,1,2三个fd文件描述符。分别是stdin、stdout、stderr
向文件描述符中写东西通信(用户层态)#
1 | echo -e "GET / HTTP/1.0\n" 1>& 8 |
传输控制层TCP协议#
TCP和UDP是传输控制层协议。
什么是socket套接字?#
-
ip+port <---------> ip+port是一【套】,客户端和服务端的ip+port 4个要素决定唯一的一个socket -
客户端的ip是B,可以和baidu建立多少个链接?65535个
-
此时客户端B还能继续和163建立链接吗?也可以继续再次建立65535个,因为socket是【一套】4个要素,server换了就是另外一个socket了。
-
对于类似如下
netstat -anp出来的socket链接,每一个established都有一个文件描述符(fd目录下)数字和他对应并交给一个进程。程序只用和这个文件描述符进行读写就可以进行socket通信了。【如果多个socket对应一个进程:就是多路复用器selector或者epoll】下面的
192.168.150.12:22建立了两个到192.168.150.1的socket: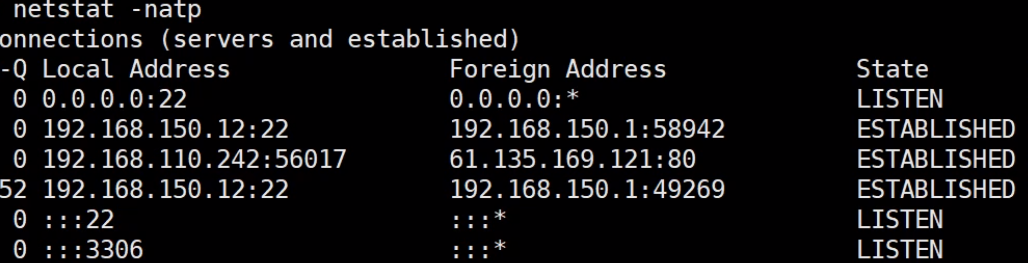
什么是TCP协议?#
是一个面向连接的可靠的传输协议。因为三次握手保证了可靠传输。
连接:不是物理连接,是三次握手实现的逻辑连接,完成双向确认。
为啥可靠:通信前三次握手双方分配资源,为未来的通讯做好了准备。所有数据包发送的时候有个确认机制保证了可靠。
DDOS:发握手包,但是不回。造成服务器有一大堆接受TCP的等待队列。使得真正想进来的连接进不来。
三次握手的细节?#
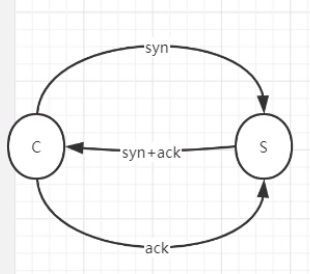
C-----------syn----------->S # “我要跟你连接了,标识是syn”
C<----------syn+ack-------S # “好的,我知道了” 让客户端知道Server已经响应了
C------------ack----------->S # 好的,我知道你知道了。让Server知道发出的消息客户端收到了
然后双方开始开辟资源(内存,结构体,线程),建立连接。
谁触发三次握手?目的?#
应用层的程序先告诉内核,我要和一个地址建立连接。内核去尝试三次握手。
三次握手成功后会在双方服务器开辟资源(线程、内存结构体等等)来为对方提供响应服务。
三次握手完毕后,双方才有资源开辟,才能开始传输。
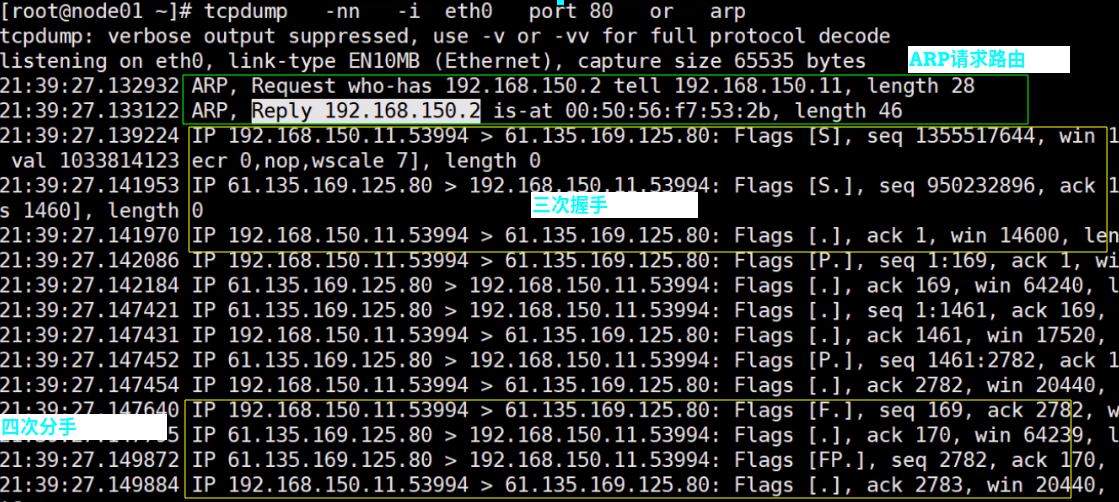
tcpdump 查看三次握手#
tcpdump -nn 显示ip断开 -i 显示哪个网卡接口 port 显示哪个端口

四次分手的细节,为啥要四次?#
因为握手是三次,开辟了资源。分手是双方一起释放资源,对对方有义务的,所以是四次(双方都要同时释放,不能轻易单方面释放了)
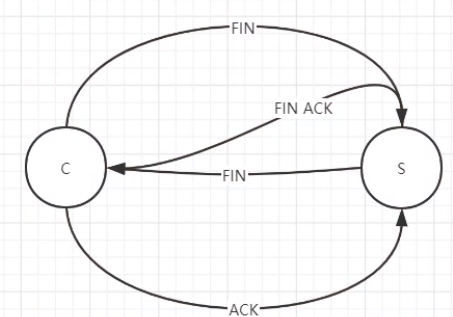
分手的C只是先说断开的人
C-----------fin----------->S # “我要跟你分手了,标识是fin”给Server一个结束标识
C<----------fin+ack-------S # “好的,我知道了” 让客户端知道Server已经响应了(但是我要确认一下真的没事儿了)
C<-----------fin------------S # “好吧,分吧,标识是fin”确认真的没事儿了,给客户端一个结束标识
C------------ack----------->S # “好的,”让Server知道发出的消息客户端收到了
然后双方把给对方准备的资源都释放了。
三次握手和四次分手是不可分割的最小粒度#
-
LVS作为一个工作在四层的负载均衡,是无法知晓数据包的具体内容的!
-
LVS是否可以随意把数据给后端进行负载?-可以负载,但是受制于协议约束!
- C ----- lvs ----- S1/S2 的时候,LVS必须要把握手的三次给到一对C—S,不能给到另外一个S,否则无法建立连接。
网络和路由#
上面的TCP协议只管传输和控制,也就是发什么内容,怎么发。但是发送的路径不管,是下层寻址ARP协议管理的。
网络设置要ip、gateway、mask、dns4个东西
- 如果几个设备ip:
192.168.1.10、192.168.1.11,他们只要成功联网,肯定知道他们的下一跳路由器地址(静态或者DHCP),如192.168.1.1 - 客户端向发送一个ARP广播包,带着路由器的ip和全
FFFFFFFFFF的mac地址,路由器收到后看到是自己的ip,就把自己的mac地址返回给客户机。 - 然后客户端才知道路由器的mac,包装后就能往百度发了三次握手的包了。
- 通过路由表往下一跳发
【测试】``
下面会先去请求ARP,收到路由器返回mac后,包装三次握手的包发出去。最后四次分手。
每次发送的包和接受的包都有一个seq和seq+1的关系,保证了不会错乱。
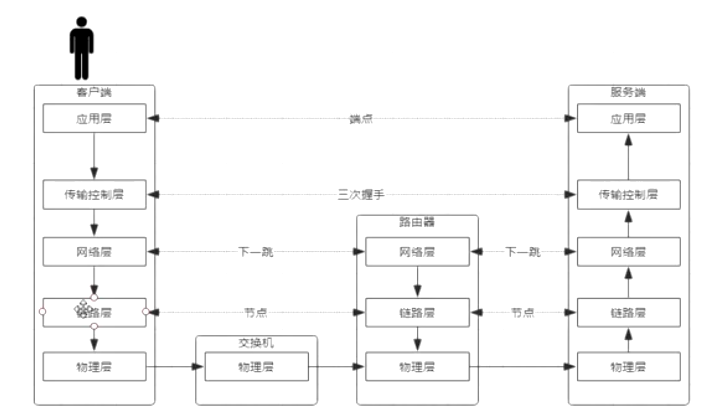
- socket是一层规范,屏蔽内核里面的四层握手等细节。应用7层只用拿到socket就能通讯,不用管里层实现。
- 四层只能看到ip和端口,看不到类似url这种七层的东西。
- lvs快就是因为是四层,但是不会和客户端握手,直接转给后面的服务集群。
负载均衡模式#
假设现在有很多的客户端,很多的server,需要中间有一个负载均衡软件去做分发。
负载均衡
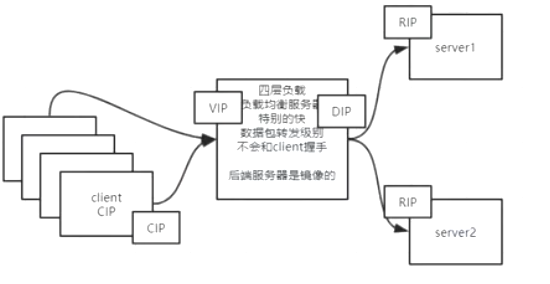
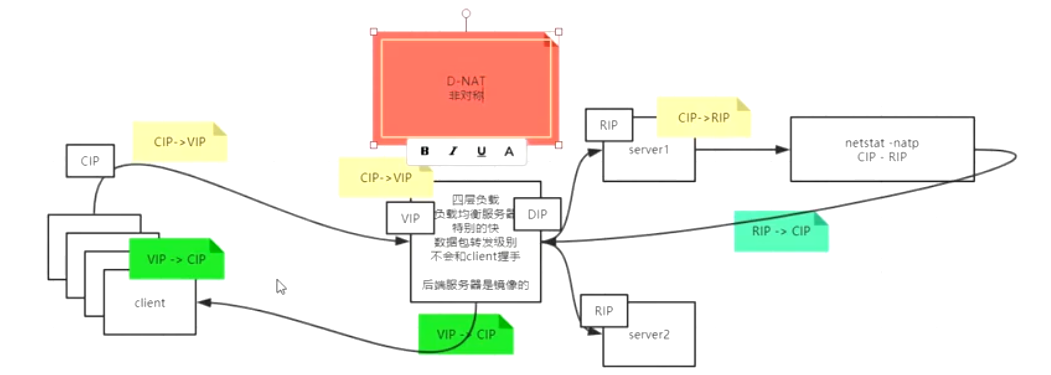
D-NAT#
- 客户端需要请求负载均衡,负载均衡转给server
- 客户端的网卡IP假设为CIP
- 负载均衡的入口网卡是VIP,出口分发网卡是DIP
- 服务端ip是RIP真实IP
- 流程:
- 不处理和client的握手,直接透传给后端server
- 多个客户端会产生
CIPx:随机port -->VIP:Vport的数据包 - VIP为了把报给server正常处理,必须把目标IP改为某个server的
RIP。 - server拿到包处理完之后,返回
RIPx--->CIPx的包,不过还是会丢给负载均衡DIP去处理。 - 负载均衡DIP网卡拿到包之后,根据目标CIPx的信息,修改来源为
VIPx--->CIPx再发回去
- 特点:
- 来回都经过负载均衡,通讯是不对称的(请求经常很小,但是响应经常很大),带宽成为瓶颈
- 负载均衡需要经过计算,去映射
- 同时因为server的包回去的时候要给到负载均衡才能正确映射到Client,所以要求server的默认网关指向负载均衡服务器。
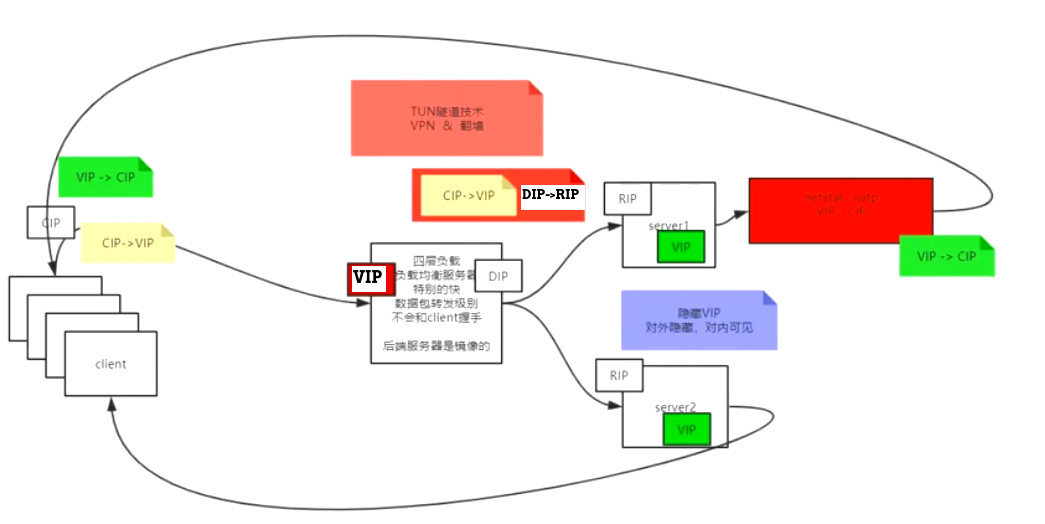
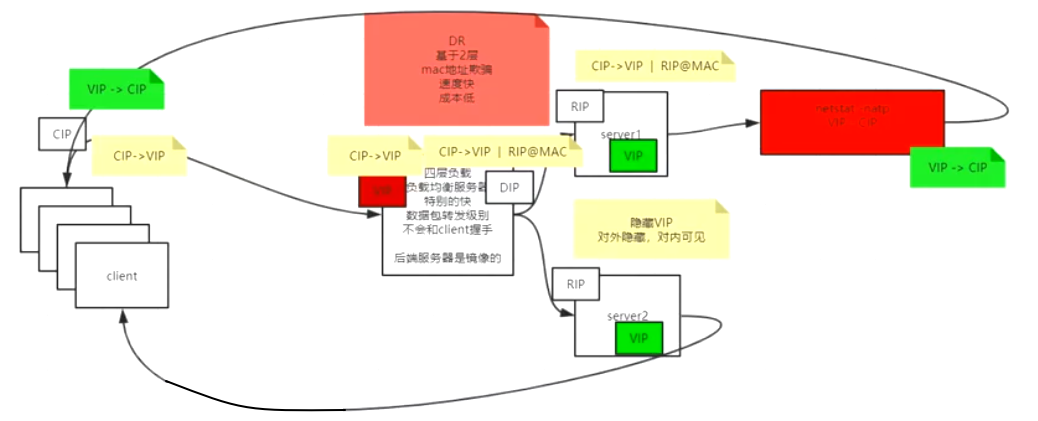
DR模式(Direct Route)#
IP和上面相同,为了解决D-NAT模式来回的非对称网络给负载均衡的压力,同时为了降低负载均衡的计算开销。
一句话:基于二层链路层的MAC地址欺骗,速度快、成本低。不过要求负载和server在同一局域网。----企业数据中心最常用
关键点:
- 第一个问题:
- 现在只要server能直接返回包给client的CIP问题就解决了。但是客户端过来的时候是
CIP--->VIP的包,回去的时候要是VIP--->CIP的包客户端才能处理。 - 比如
natstat -natp的时候有本地和对端的ip:port <---->ip:port映射,我们要在server上伪造一个隐藏的负载均衡IP不被网络发现。就可以伪造一对socket映射。 - 同理所有的server内部原本都是RIP,现在都伪造了一块隐藏的VIP网卡。
- 第二个问题:
- 负载均衡要把包发给各个server的时候无需在三层网络层IP的层面去解开然后修改IP,只需要修改下一跳的二层链路层的MAC地址为某一个server的MAC即可。
- 回忆上面TCP/IP基于下一跳机制,这里是一样的,因为VIP接收到的数据包就是
CIP--->VIP,server又有隐藏的VIP网卡。所以负载均衡直接进行MAC地址欺骗,篡改MAC为某个server的MAC,链路层就能把包发给对应的server去处理。(如果不改,这个数据包就会又发给负载均衡器自己) - 数据包的IP是两个端点的,MAC是下一跳的。
- 这样在二层直接改链路的MAC,非常快。但是缺点是只能是同一个局域网内。也就是要求负载均衡和server是同一个局域网内。
- 然后server处理完之后,直接就把包从server返回给CIP客户端,无需再次经过负载均衡。
- 图上看不清的右边红色部分是
netstat -natp
TUN隧道技术#
实现:
- 隧道,通俗理解即一个数据包背着另外一个数据包。也就是外层数据包,里面包裹着一个内层数据包。
- 比如client访问server其实先访问负载均衡的VIP,负载均衡的VIP使用分发网卡DIP去往真正的serverRIP,里面包装了一个
CIP-->VIP客户端请求包。 - 然后又可以继续不停地经过下一跳机制,到达server的RIP。server拆掉外面的数据包,就看到了里面的
CIP-->VIP的包,进行处理。 - 处理完毕server直接返回给客户端(server上有VIP的隐藏网卡)
- 常规的VPN和科学地上网都是类似的原理。