CacheLine简介
CPU缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,目前主流的CPU Cache的Cache Line大小都是64Bytes(和操作系统、CPU有关)。**当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。**缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。
由于共享变量在CPU缓存中的存储是以缓存行为单位,一个缓存行可以存储多个变量(存满当前缓存行的字节数);而CPU对缓存的修改又是以缓存行为最小单位的,如果多线程同时修改同一缓存行上的两个变量,那么就会出现上诉的伪共享问题。
伪共享是无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。对于多线程编程来说,特别是多线程处理列表和数组的时候,要非常注意伪共享的问题。否则不仅无法发挥多线程的优势,还可能比单线程性能还差。
为什么CacheLine并发慢?
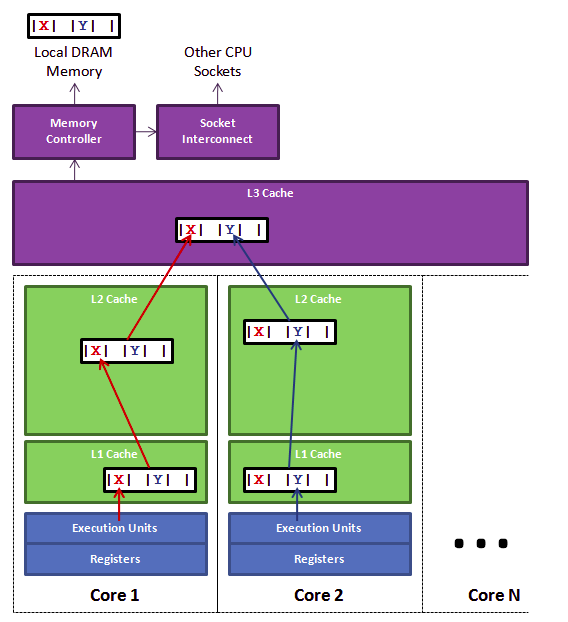
- 下面的图中,X和Y在同一缓存行中,读取的时候只能一起从“内存–L3–L2–L1–寄存器”去加载。使用的时候反着从“寄存器-L1-L2-L3-主存”去拿,走得越远越慢。
- 所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
- 但是当core1修改X的时候,把这个CacheLine读取进来修改完毕,根据MESI缓存一致性协议,缓存行会失效。需要从下级Cache或者其他核心的Cache,甚至主存重新load。
MESI缓存一致性协议
是多种一致性协议中的一种实现,规定缓存在同一时间只有一种状态:
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
I(Invalid):这行数据无效。
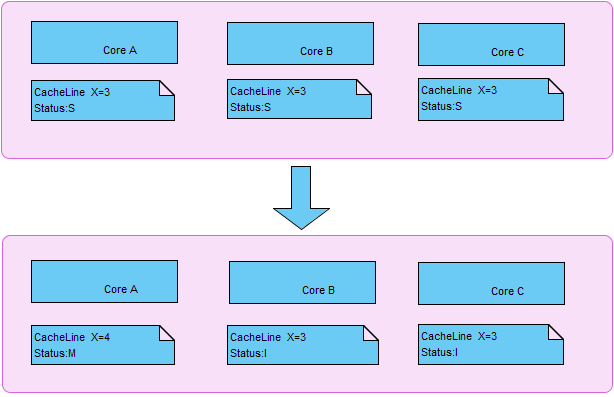
那么,假设有一个变量i=3(应该是包括变量i的缓存块,块大小为缓存行大小);
已经加载到多核(a,b,c)的缓存中,此时该缓存行的状态为S(Share共享有效);
此时其中的一个核a改变了变量i的值,那么在核a中的当前缓存行的状态将变为M(有效但修改了,和内存不一致),b,c核中的当前缓存行状态将变为I(无效)。如下图:
FalseSharing伪共享问题
在上面的情况下a核心修改后缓存状态变为M,b和c核心的缓存变为I无效,去重新load(从其他核心的缓存中同步,或者从主存同步,看CPU实现了)。
此时在核b上运行的线程,正好想要修改变量Y,那么就会出现相互竞争,相互失效的情况,这就是伪共享啦。
伪共享的解决方案
下面使用一个带有long类型的简单对象来测试(使用一个long数组测试也行,略不直观)
原始有缓存行竞争的问题
如下,假设一个数组有多个Obj1对象。我们多线程需要对不同位置的Obj1的x进行并发赋值,在修改的时候会因为一次load了多个Obj1到内存中,就会产生缓存行互相失效的竞争问题。这就是原始的伪共享问题。
1
2
3
4
5
6
7
8
9
10
|
abstract class Obj{
long x;
}
class Obj1 extends Obj{
long x;
}
|
JDK8以前人肉解决:
前后各加8个long(64位)来规避缓存行竞争,在诸如Disruptor等追求极致性能的地方会见到这种代码:
1
2
3
4
5
6
7
8
9
10
|
class Obj2 extends Obj{
long p1,p2,p3,p4,p5,p6,p7;
long x;
long p8,p9,p10,p11,p12,p13,p14;
}
|
JDK8以后@Contended解决:
使用@Contended注解自动进行缓存行填充,防止多线程竞争缓存行。JVM会给我们前后各加128bit的padding,保证规避了缓存行竞争。
1
2
3
4
5
6
7
8
|
@Contended
class Obj3 extends Obj{
long x;
}
|
确认内存布局
我们的两种优化是不是真的有效呢?JOL看一下这三个对象的内存布局:
1
2
3
4
5
6
| Obj1 obj1 = new Obj1();
Obj2 obj2 = new Obj2();
Obj3 obj3 = new Obj3();
System.out.println(ClassLayout.parseInstance(obj1).toPrintable());
System.out.println(ClassLayout.parseInstance(obj2).toPrintable());
System.out.println(ClassLayout.parseInstance(obj3).toPrintable());
|
可以看到:
- 没加缓存行优化的Obj1:我们的核心属性,前后没有缓存行对齐,直接多线程修改它是有伪共享问题的(两个Obj1的x在同一个缓存行中)
- 使用人肉8个long进行缓存行优化的Obj2:我们的核心属性,前后都有64位的填充,多线程竞争也不会使得两个Obj2对象的x在同一个缓存行中
- 使用JDK自带@Contended修饰的Obj3:前后各有一个长达128字节的填充,多线程竞争也不会使得两个Obj2对象的x在同一个缓存行中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
com.xxxx.Obj1 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 81 c1 00 f8 (10000001 11000001 00000000 11111000) (-134168191)
12 4 (alignment/padding gap)
16 8 long Obj.x 0
24 8 long Obj1.x 0
Instance size: 32 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
com.xxxx.Obj2 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) bf c1 00 f8 (10111111 11000001 00000000 11111000) (-134168129)
12 4 (alignment/padding gap)
16 8 long Obj.x 0
24 8 long Obj2.p1 0
32 8 long Obj2.p2 0
40 8 long Obj2.p3 0
48 8 long Obj2.p4 0
56 8 long Obj2.p5 0
64 8 long Obj2.p6 0
72 8 long Obj2.p7 0
80 8 long Obj2.x 0
88 8 long Obj2.p8 0
96 8 long Obj2.p9 0
104 8 long Obj2.p10 0
112 8 long Obj2.p11 0
120 8 long Obj2.p12 0
128 8 long Obj2.p13 0
136 8 long Obj2.p14 0
Instance size: 144 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
com.xxxx.Obj3 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c2 00 f8 (00000101 11000010 00000000 11111000) (-134168059)
12 4 (alignment/padding gap)
16 8 long Obj.x 0
24 128 (alignment/padding gap)
152 8 long Obj3.x 0
160 128 (loss due to the next object alignment)
Instance size: 288 bytes
Space losses: 132 bytes internal + 128 bytes external = 260 bytes total
|
效果测试
下面是工具方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
private static void testCacheLine(Obj[] arr) throws InterruptedException {
StopWatch watch = new StopWatch();
watch.start();
long times = 1_0000_0000l;
CountDownLatch latch = new CountDownLatch(2);
new Thread(()->{
for (Long i = 0l; i < times; i++) {
arr[0].x = i;
}
latch.countDown();
}).start();
new Thread(()->{
for (Long i = 0l; i < times; i++) {
arr[1].x = i;
}
latch.countDown();
}).start();
latch.await();
watch.stop();
System.out.println(watch.getTime());
}
|
测试原始问题、人肉优化、@Contended优化。
注意@Contended需要运行的时候加上-XX:-RestrictContended参数才生效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public static void main(String[] args) {
try {
Obj [] arr1 = new Obj1[2];
arr1[0] = new Obj1();
arr1[1] = new Obj1();
testCacheLine(arr1);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Obj [] arr2 = new Obj2[2];
arr2[0] = new Obj2();
arr2[1] = new Obj2();
testCacheLine(arr2);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Obj [] arr3 = new Obj3[2];
arr3[0] = new Obj3();
arr3[1] = new Obj3();
testCacheLine(arr3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
|
多次运行可以发现未优化的速度明显慢于后两者优化后的:
后两者优化后的差异不大,通常都很接近。
也可参见美团的一篇disruptor文章中的测试:
https://tech.meituan.com/2016/11/18/disruptor.html